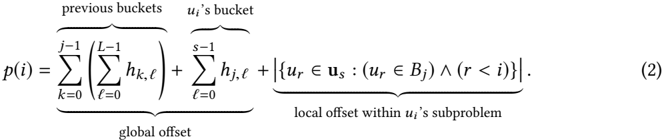## Mathematical Equation Diagram: Probability Function p(i) with Bucket Offsets
### Overview
The image displays a mathematical equation, labeled as equation (2), defining a function `p(i)`. The equation is annotated with descriptive text that breaks down its components into conceptual parts related to "buckets," "global offset," and "local offset." The notation suggests a context involving partitioned data structures or algorithms, possibly in computer science or optimization.
### Components/Axes
The image contains a single, centered mathematical expression with the following textual elements:
* **Main Equation Label:** `(2)` is positioned to the far right of the equation.
* **Equation:** `p(i) = [Summation Term 1] + [Summation Term 2] + [Set Cardinality Term]`
* **Annotations (Above the Equation):**
* Above the first summation: `previous buckets`
* Above the second summation: `u_i's bucket`
* **Annotations (Below the Equation):**
* Below the first two summation terms: `global offset`
* Below the set cardinality term: `local offset within u_i's subproblem`
### Detailed Analysis
The equation is transcribed precisely as follows:
**Equation (2):**
`p(i) = ∑_{k=0}^{J-1} (∑_{ℓ=0}^{L-1} h_{k,ℓ}) + ∑_{ℓ=0}^{s-1} h_{j,ℓ} + |{u_r ∈ u_s : (u_r ∈ B_j) ∧ (r < i)}|`
**Component Breakdown:**
1. **First Term (Annotated "previous buckets" / part of "global offset"):**
* `∑_{k=0}^{J-1}` : A summation over index `k` from 0 to `J-1`.
* `(∑_{ℓ=0}^{L-1} h_{k,ℓ})` : The summand is itself a summation over index `ℓ` from 0 to `L-1` of the term `h_{k,ℓ}`. The parentheses group this inner sum for each `k`.
2. **Second Term (Annotated "u_i's bucket" / part of "global offset"):**
* `∑_{ℓ=0}^{s-1} h_{j,ℓ}` : A summation over index `ℓ` from 0 to `s-1` of the term `h_{j,ℓ}`. The index `j` is not bound by this summation and is likely a fixed parameter related to `u_i`.
3. **Third Term (Annotated "local offset within u_i's subproblem"):**
* `|{ ... }|` : The cardinality (size) of a set.
* Set Definition: `{u_r ∈ u_s : (u_r ∈ B_j) ∧ (r < i)}`
* `u_r ∈ u_s` : Elements `u_r` that are members of a collection `u_s`.
* `(u_r ∈ B_j)` : The condition that element `u_r` is also in a bucket or set `B_j`.
* `∧` : Logical AND operator.
* `(r < i)` : The condition that the index `r` is less than the function argument `i`.
### Key Observations
* The equation is structured as a sum of three distinct components, each with an explanatory annotation.
* The first two terms are pure summations of `h` values and are collectively labeled as a "global offset." The first term aggregates over `J` previous buckets, each containing `L` items. The second term aggregates over a specific bucket (`u_i's bucket`) containing `s` items.
* The third term is a counting function (cardinality) based on set membership and an index comparison, labeled as a "local offset." It counts elements `u_r` that satisfy two conditions: belonging to a specific bucket `B_j` and having an index `r` less than `i`.
* The use of indices (`i, j, k, ℓ, r`) and set notation (`∈, ∧`) indicates a formal, discrete mathematical context.
### Interpretation
This equation defines a function `p(i)` that appears to calculate a position, price, probability, or priority score for an element indexed by `i`. The structure suggests a system where items are organized into a hierarchy of "buckets."
* **What it demonstrates:** The value `p(i)` is computed as the sum of:
1. A **global base value** derived from all preceding buckets (`k=0` to `J-1`) and the current bucket (`u_i's bucket`).
2. A **local adjustment** that depends on the specific position (`i`) of the element within its subproblem. This adjustment counts how many elements in the same bucket (`B_j`) as `u_i` have an index smaller than `i`.
* **Relationship between elements:** The "global offset" provides a baseline determined by the bucket structure. The "local offset" then fine-tunes this baseline based on the element's ordinal position within its local group, creating a unique value for each `i`.
* **Potential Context:** This formulation is characteristic of algorithms dealing with **priority queues, memory allocation, or scheduling**, where `p(i)` could represent a key for ordering, an address offset, or a timestamp. The "buckets" likely represent groups of tasks or data blocks, and the equation ensures a total ordering that respects both group-level and intra-group priorities. The explicit separation into global and local components is a common technique for designing efficient data structures.