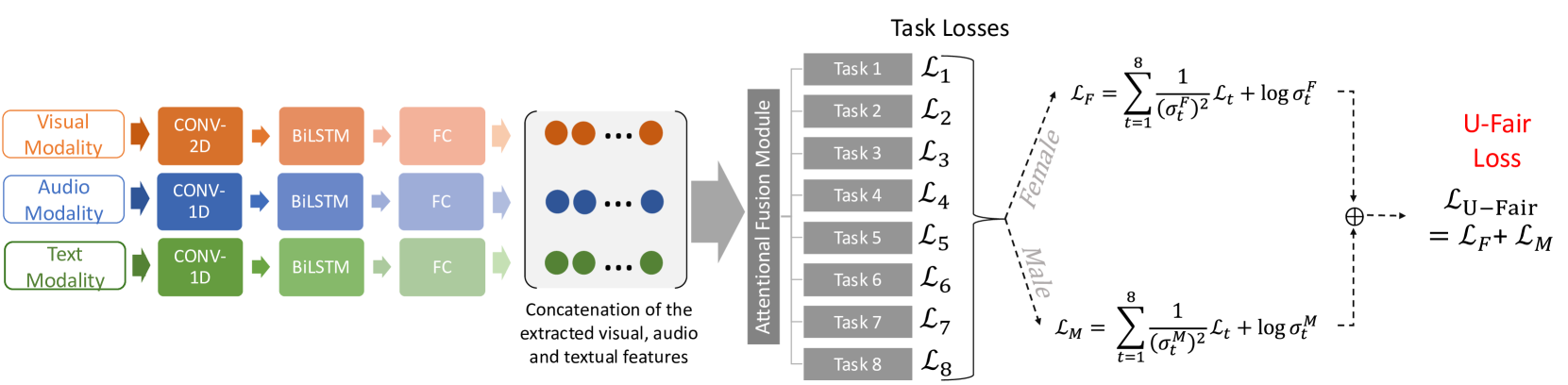
## Diagram: Multi-Modal Fusion System with Task-Specific Losses
### Overview
The diagram illustrates a multi-modal machine learning system that processes visual, audio, and textual modalities through distinct neural network architectures. These modalities are then fused via an attention mechanism to compute task-specific losses, including a fairness-aware "U-Fair Loss" component. The system emphasizes gender fairness through separate loss calculations for female and male representations.
### Components/Axes
**Left Section (Input Processing):**
- **Visual Modality**:
- Conv-2D → BiLSTM → FC (Fully Connected)
- Represented by orange color
- **Audio Modality**:
- Conv-1D → BiLSTM → FC
- Represented by blue color
- **Text Modality**:
- Conv-1D → BiLSTM → FC
- Represented by green color
- **Attentional Fusion Module**:
- Combines extracted features from all modalities
- Depicted as a gray box with concatenation arrows
**Right Section (Task Losses):**
- **Task Losses (L₁–L₈)**:
- Eight task-specific loss components
- Labeled as "Task 1" to "Task 8"
- **U-Fair Loss Equation**:
- `L_U-Fair = L_F + L_M`
- `L_F = Σₜ=1⁸ [1/(σ_Fᵗ)² * L_t + log σ_Fᵗ]`
- `L_M = Σₜ=1⁸ [1/(σ_Mᵗ)² * L_t + log σ_Mᵗ]`
- Includes gender-specific fairness terms (Female/Male)
### Detailed Analysis
**Left Section Flow:**
1. **Modality-Specific Processing**:
- Visual: 2D convolutional layers capture spatial features
- Audio/Text: 1D convolutional layers extract temporal/sequential patterns
- All modalities use Bidirectional LSTMs (BiLSTM) for sequence modeling
- Final fully connected (FC) layers reduce dimensionality
2. **Feature Concatenation**:
- Extracted features from all modalities are concatenated
- Visual (orange), audio (blue), and text (green) features are stacked vertically
**Right Section Flow:**
1. **Task Loss Calculation**:
- Eight independent task losses (L₁–L₈) are computed
- Each task loss contributes to both female (L_F) and male (L_M) fairness components
2. **Fairness-Aware Loss**:
- Female fairness term (`L_F`) uses σ_Fᵗ parameters
- Male fairness term (`L_M`) uses σ_Mᵗ parameters
- Final U-Fair Loss combines both fairness components
### Key Observations
1. **Modality-Specific Architectures**:
- Visual uses 2D convolutions (spatial features)
- Audio/Text use 1D convolutions (temporal features)
- All modalities converge through BiLSTM layers
2. **Fairness Mechanism**:
- Separate fairness parameters (σ_F, σ_M) for gender representation
- Logarithmic terms in fairness loss suggest regularization of confidence
3. **Attention Fusion**:
- Implicit attention mechanism in the fusion module
- No explicit attention weights shown, but concatenation implies feature combination
### Interpretation
This system demonstrates a fairness-aware multi-modal learning framework where:
1. **Modality Integration**: Distinct neural architectures preserve modality-specific features before fusion
2. **Task Specialization**: Eight independent tasks are optimized with shared modality features
3. **Fairness Constraints**: The U-Fair Loss explicitly balances gender representation through:
- Inverse variance weighting (1/σ²) of task losses
- Logarithmic regularization of fairness parameters
4. **Architectural Choices**:
- BiLSTMs handle sequential data in audio/text
- 2D convolutions capture spatial relationships in visual data
- FC layers enable cross-modal integration
The system's design suggests a focus on maintaining gender fairness across multiple tasks while leveraging modality-specific processing strengths. The fairness loss formulation implies a probabilistic interpretation of representation confidence (σ terms) that regularizes gender-specific predictions.