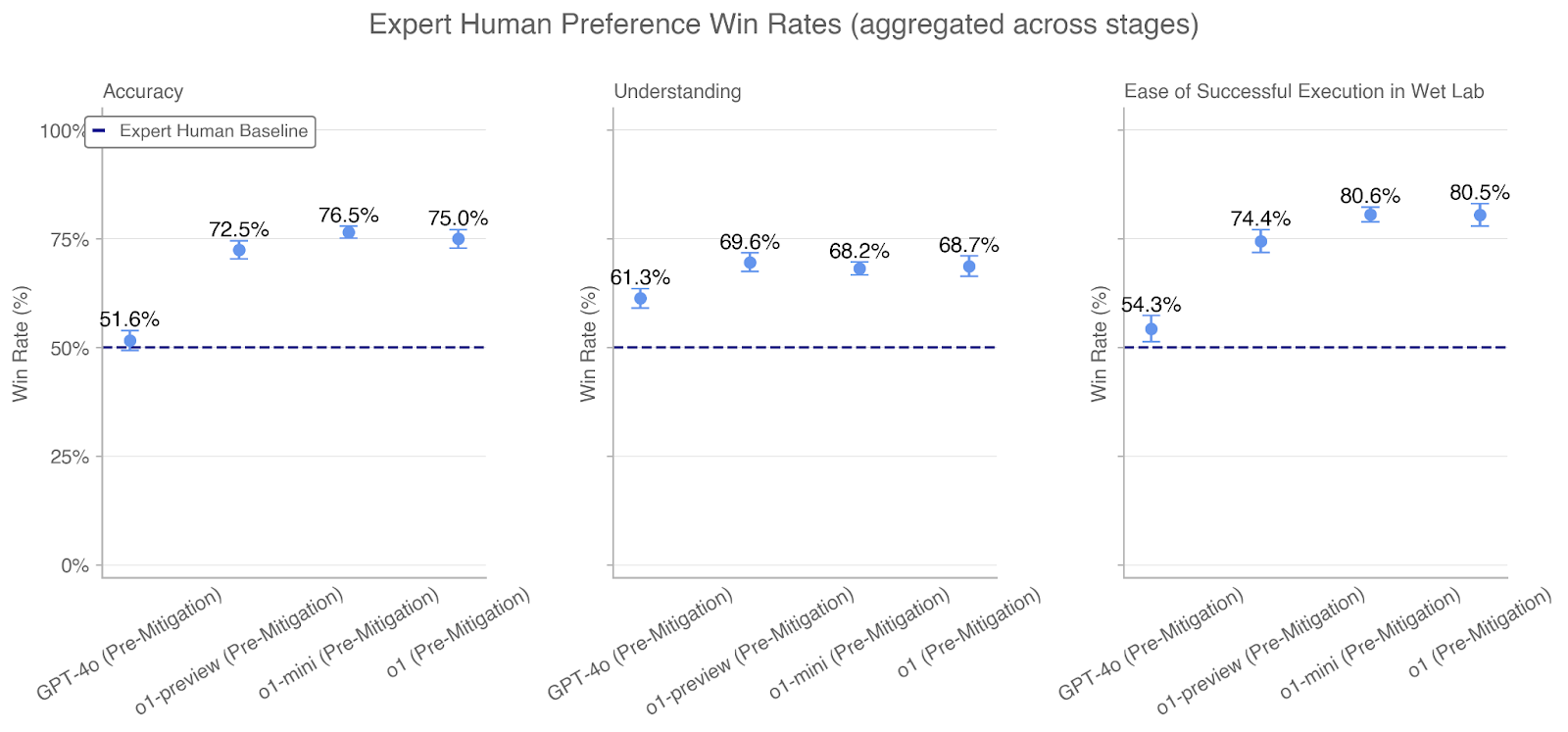
## Chart: Expert Human Preference Win Rates
### Overview
The image presents three separate line charts comparing the "Win Rate (%)" of different models (GPT-4o, o1-preview, o1-mini, and o1) against an "Expert Human Baseline" across three different metrics: "Accuracy", "Understanding", and "Ease of Successful Execution in Wet Lab". All models are evaluated in a "Pre-Mitigation" state. The x-axis represents the different models, and the y-axis represents the win rate in percentage. Each data point is represented by a blue circle with error bars. A dashed blue line indicates the "Expert Human Baseline" at approximately 51.6% for Accuracy, 50% for Understanding, and 54.3% for Ease of Successful Execution in Wet Lab.
### Components/Axes
* **Title:** Expert Human Preference Win Rates (aggregated across stages)
* **X-axis:**
* Labels: GPT-4o (Pre-Mitigation), o1-preview (Pre-Mitigation), o1-mini (Pre-Mitigation), o1 (Pre-Mitigation)
* **Y-axis:**
* Label: Win Rate (%)
* Scale: 0%, 25%, 50%, 75%, 100%
* **Legend:** Located in the top-left corner of the "Accuracy" chart.
* Blue Dashed Line: Expert Human Baseline
* **Charts:**
* Left Chart: Accuracy
* Middle Chart: Understanding
* Right Chart: Ease of Successful Execution in Wet Lab
### Detailed Analysis
#### Accuracy Chart
* **Trend:** The win rate generally increases from GPT-4o to o1-mini, then slightly decreases for o1. All models outperform the Expert Human Baseline.
* **Data Points:**
* GPT-4o (Pre-Mitigation): 51.6%
* o1-preview (Pre-Mitigation): 72.5%
* o1-mini (Pre-Mitigation): 76.5%
* o1 (Pre-Mitigation): 75.0%
* **Expert Human Baseline:** 51.6%
#### Understanding Chart
* **Trend:** The win rate increases from GPT-4o to o1-preview, then decreases slightly for o1-mini and o1. All models outperform the Expert Human Baseline.
* **Data Points:**
* GPT-4o (Pre-Mitigation): 61.3%
* o1-preview (Pre-Mitigation): 69.6%
* o1-mini (Pre-Mitigation): 68.2%
* o1 (Pre-Mitigation): 68.7%
* **Expert Human Baseline:** 50%
#### Ease of Successful Execution in Wet Lab Chart
* **Trend:** The win rate increases from GPT-4o to o1-mini, then slightly decreases for o1. All models outperform the Expert Human Baseline.
* **Data Points:**
* GPT-4o (Pre-Mitigation): 54.3%
* o1-preview (Pre-Mitigation): 74.4%
* o1-mini (Pre-Mitigation): 80.6%
* o1 (Pre-Mitigation): 80.5%
* **Expert Human Baseline:** 54.3%
### Key Observations
* All models (GPT-4o, o1-preview, o1-mini, and o1) outperform the Expert Human Baseline across all three metrics (Accuracy, Understanding, and Ease of Successful Execution in Wet Lab).
* The "o1-mini" model generally achieves the highest win rates, especially for "Accuracy" and "Ease of Successful Execution in Wet Lab".
* The "GPT-4o" model consistently shows the lowest win rates compared to the other models.
* The win rates for "Ease of Successful Execution in Wet Lab" are generally higher than those for "Accuracy" and "Understanding".
### Interpretation
The data suggests that the "o1" family of models (o1-preview, o1-mini, and o1) represents a significant improvement over the GPT-4o model in terms of expert human preference, as measured by accuracy, understanding, and ease of successful execution in a wet lab setting. The fact that all models outperform the Expert Human Baseline indicates that these AI models are demonstrating capabilities that are preferred by human experts. The slight decrease in win rate from "o1-mini" to "o1" in most metrics could suggest that "o1-mini" represents an optimal configuration or that further development in "o1" introduced trade-offs. The higher win rates for "Ease of Successful Execution in Wet Lab" might indicate that the models are particularly strong in tasks related to practical application and implementation.