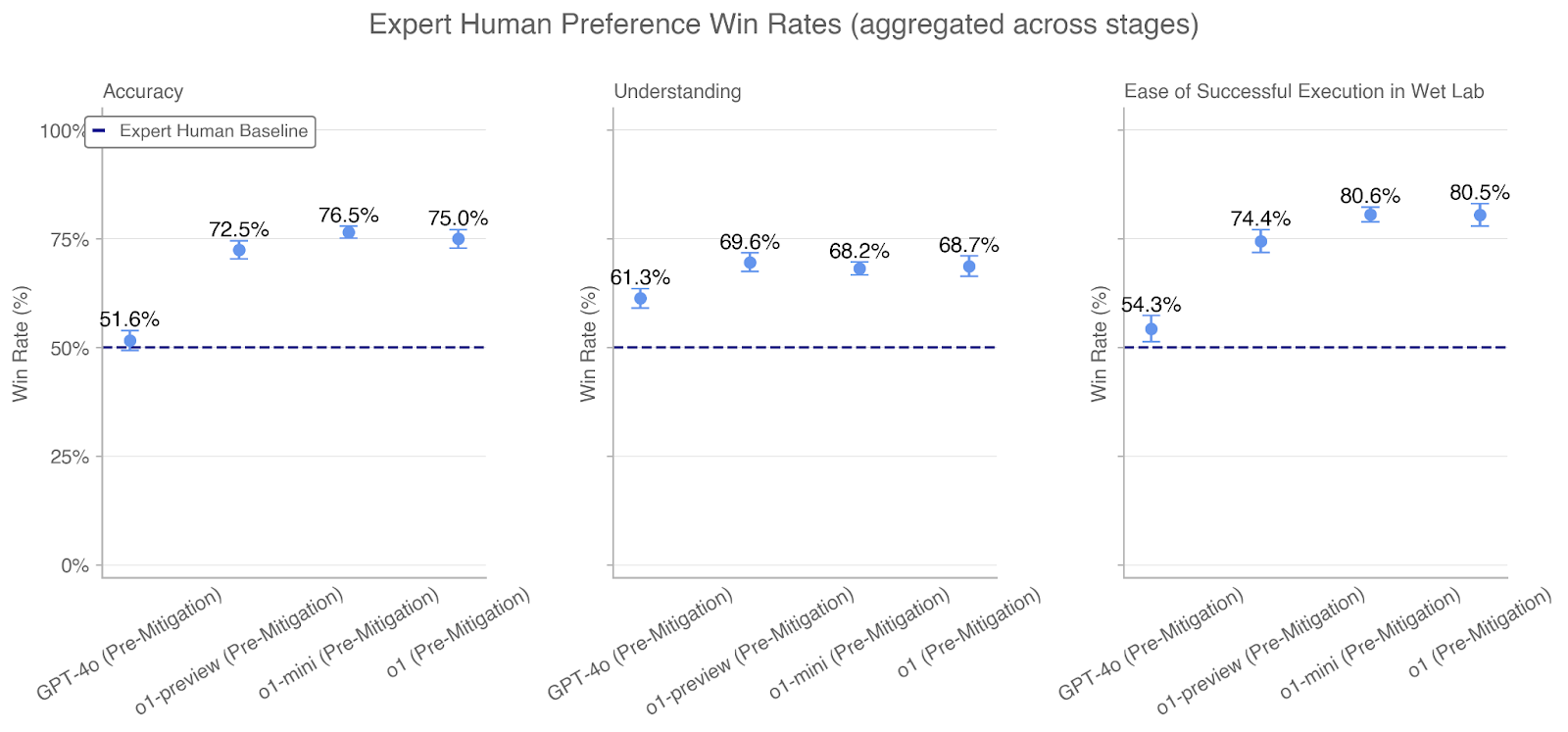
\n
## Chart: Expert Human Preference Win Rates (aggregated across stages)
### Overview
This image presents three separate line charts, arranged horizontally, displaying "Expert Human Preference Win Rates" across different stages. Each chart focuses on a different metric: Accuracy, Understanding, and Ease of Successful Execution in Wet Lab. The charts compare the win rates of GPT-4o (Pre-Mitigation), o1-preview (Pre-Mitigation), o1-mini (Pre-Mitigation), and o1 (Pre-Mitigation) against an "Expert Human Baseline".
### Components/Axes
* **Title:** Expert Human Preference Win Rates (aggregated across stages)
* **X-axis (all charts):** Model/Stage - GPT-4o (Pre-Mitigation), o1-preview (Pre-Mitigation), o1-mini (Pre-Mitigation), o1 (Pre-Mitigation)
* **Y-axis (all charts):** Win Rate (%) - Scale ranges from 0% to 100%, with increments of 25%.
* **Baseline:** A horizontal dashed line representing the "Expert Human Baseline" at 50%.
* **Data Series:** Four lines representing the win rates for each model/stage.
* **Error Bars:** Vertical lines indicating the uncertainty around each data point.
* **Legend:** Located in the top-left corner of the first chart (Accuracy), indicating the "Expert Human Baseline" is represented by a dashed line.
### Detailed Analysis or Content Details
**Chart 1: Accuracy**
* **Trend:** The line representing the win rates generally slopes upward from GPT-4o to o1.
* GPT-4o (Pre-Mitigation): Approximately 72.5% win rate, with an uncertainty range extending roughly ± 3%.
* o1-preview (Pre-Mitigation): Approximately 76.5% win rate, with an uncertainty range extending roughly ± 3%.
* o1-mini (Pre-Mitigation): Approximately 75.0% win rate, with an uncertainty range extending roughly ± 3%.
* o1 (Pre-Mitigation): Approximately 75.0% win rate, with an uncertainty range extending roughly ± 3%.
* Expert Human Baseline: 51.6%
**Chart 2: Understanding**
* **Trend:** The line representing the win rates generally slopes upward from GPT-4o to o1.
* GPT-4o (Pre-Mitigation): Approximately 61.3% win rate, with an uncertainty range extending roughly ± 3%.
* o1-preview (Pre-Mitigation): Approximately 69.6% win rate, with an uncertainty range extending roughly ± 3%.
* o1-mini (Pre-Mitigation): Approximately 68.2% win rate, with an uncertainty range extending roughly ± 3%.
* o1 (Pre-Mitigation): Approximately 68.7% win rate, with an uncertainty range extending roughly ± 3%.
* Expert Human Baseline: 50%
**Chart 3: Ease of Successful Execution in Wet Lab**
* **Trend:** The line representing the win rates generally slopes upward from GPT-4o to o1.
* GPT-4o (Pre-Mitigation): Approximately 54.3% win rate, with an uncertainty range extending roughly ± 3%.
* o1-preview (Pre-Mitigation): Approximately 74.4% win rate, with an uncertainty range extending roughly ± 3%.
* o1-mini (Pre-Mitigation): Approximately 80.6% win rate, with an uncertainty range extending roughly ± 3%.
* o1 (Pre-Mitigation): Approximately 80.5% win rate, with an uncertainty range extending roughly ± 3%.
* Expert Human Baseline: 50%
### Key Observations
* All models (GPT-4o, o1-preview, o1-mini, o1) consistently outperform the "Expert Human Baseline" across all three metrics (Accuracy, Understanding, and Ease of Successful Execution).
* The largest improvements are observed in "Ease of Successful Execution in Wet Lab," where the win rates for o1-mini and o1 reach approximately 80.5-80.6%.
* The win rates for o1-mini and o1 are very similar across all three metrics.
* GPT-4o shows the lowest win rates across all metrics, but still exceeds the baseline.
### Interpretation
The data suggests that the models, particularly o1-mini and o1, demonstrate a significant improvement over expert human performance in these tasks. The consistent outperformance across all three metrics indicates a robust advantage. The substantial gains in "Ease of Successful Execution in Wet Lab" suggest that these models are particularly effective in assisting with practical, hands-on tasks. The relatively small uncertainty ranges (indicated by the error bars) suggest that these results are statistically reliable. The fact that o1-mini and o1 have similar performance suggests that the benefits of the "mini" version are comparable to the full version. The upward trend across the models indicates that the mitigation strategies implemented are effective in improving performance. The baseline of 50% suggests that the human experts were not performing perfectly, leaving room for improvement through AI assistance.