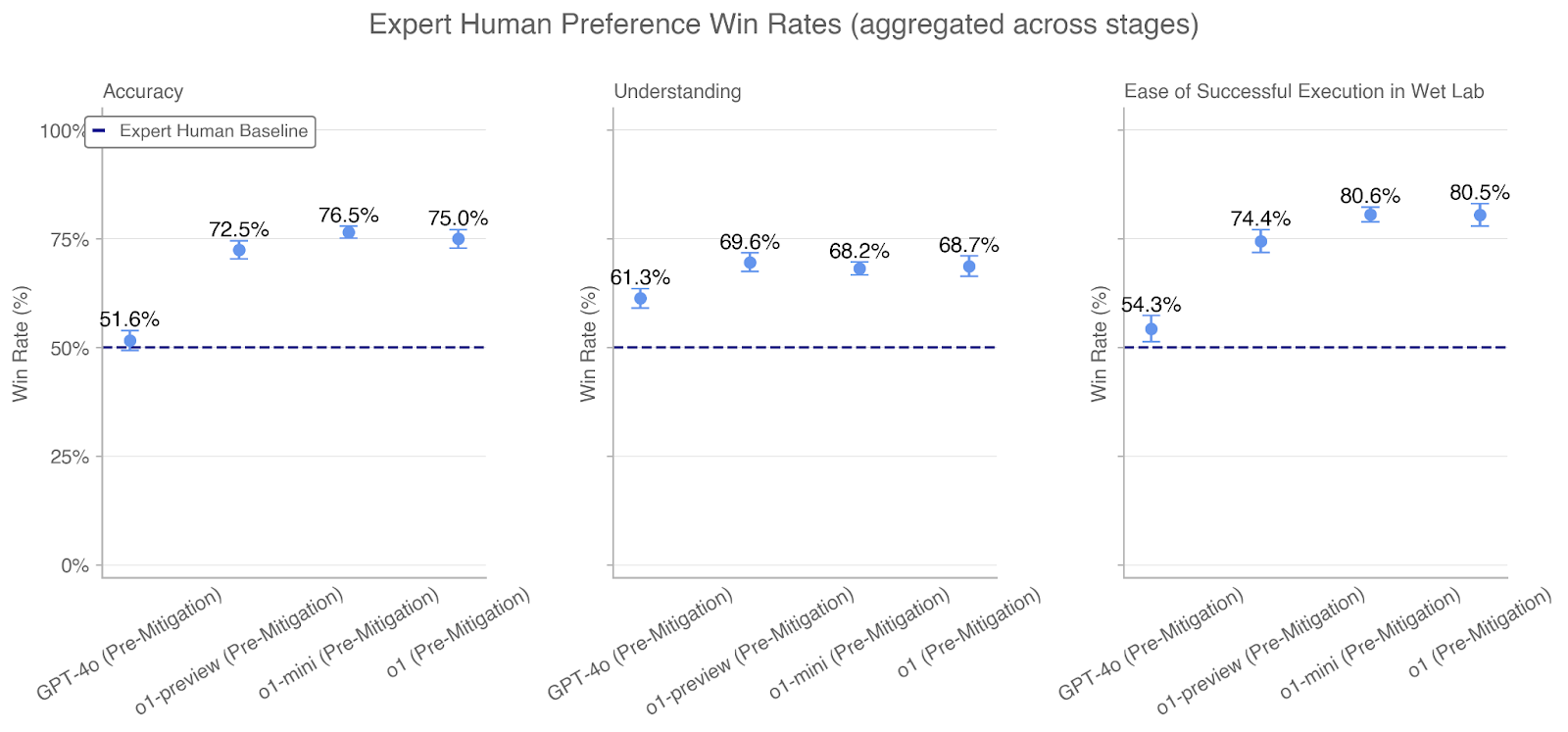
## Grouped Bar Chart: Expert Human Preference Win Rates (aggregated across stages)
### Overview
The chart compares win rates of three AI models (GPT-4o, o1-preview, o1-mini) against an "Expert Human Baseline" (50%) across three evaluation categories: Accuracy, Understanding, and Ease of Successful Execution in Wet Lab. Data is presented as percentages with error bars indicating variability.
### Components/Axes
- **X-Axes**:
- Accuracy (left sub-chart)
- Understanding (middle sub-chart)
- Ease of Successful Execution in Wet Lab (right sub-chart)
- **Y-Axes**: Win Rate (%) from 0% to 100% in all sub-charts
- **Legend**:
- Position: Top-left corner
- Label: "Expert Human Baseline" (dashed line at 50%)
- Color: Dark blue (solid line) for baseline, light blue (filled circles) for models
- **Data Points**:
- Models represented by light blue filled circles with error bars
- Baseline represented by dark blue dashed line
### Detailed Analysis
#### Accuracy Sub-Chart
- **GPT-4o**: 51.6% (±1.2%)
- **o1-preview**: 72.5% (±1.8%)
- **o1-mini**: 76.5% (±1.5%)
- **Baseline**: 50% (dashed line)
#### Understanding Sub-Chart
- **GPT-4o**: 61.3% (±1.5%)
- **o1-preview**: 69.6% (±1.7%)
- **o1-mini**: 68.2% (±1.6%)
- **Baseline**: 50% (dashed line)
#### Ease of Successful Execution Sub-Chart
- **GPT-4o**: 54.3% (±1.4%)
- **o1-preview**: 74.4% (±1.9%)
- **o1-mini**: 80.6% (±1.7%)
- **Baseline**: 50% (dashed line)
### Key Observations
1. **Universal Outperformance**: All models exceed the 50% human baseline in all categories.
2. **Category-Specific Strengths**:
- **Accuracy**: o1-mini leads (76.5%), GPT-4o barely surpasses baseline (51.6%)
- **Understanding**: o1-preview leads (69.6%), GPT-4o shows moderate performance (61.3%)
- **Ease of Execution**: o1-mini dominates (80.6%), GPT-4o lags (54.3%)
3. **Error Bar Consistency**: All models show similar variability (±1.2–1.9%), suggesting comparable data reliability.
4. **Model Hierarchy**: o1-mini > o1-preview > GPT-4o in Accuracy and Ease; o1-preview > o1-mini in Understanding.
### Interpretation
The data demonstrates that all tested AI models outperform human experts in the evaluated categories, with o1-mini showing the strongest overall performance. The stark contrast in GPT-4o's Accuracy (51.6%) versus its Ease of Execution (54.3%) suggests potential trade-offs between precision and practical application. The narrow performance gaps between models (e.g., o1-mini's 76.5% vs. o1-preview's 72.5% in Accuracy) indicate competitive parity, though o1-mini consistently edges ahead. The error bars imply measurement consistency across evaluations, though the GPT-4o's lower win rates in Accuracy and Ease warrant further investigation into its limitations. This pattern suggests AI systems may excel in specific technical domains (e.g., wet lab execution) while requiring refinement in foundational skills like accuracy.