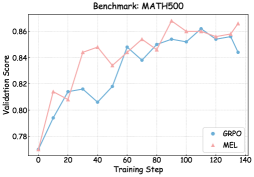
## Chart: Benchmark MATH500 Validation Score vs Training Step
### Overview
The image is a line chart comparing the validation scores of two models, GRPO and MEL, over training steps. The x-axis represents the training step, and the y-axis represents the validation score.
### Components/Axes
* **Title:** Benchmark: MATH500
* **X-axis:** Training Step, with markers at 0, 20, 40, 60, 80, 100, 120, and 140.
* **Y-axis:** Validation Score, ranging from 0.78 to 0.86, with markers at 0.78, 0.80, 0.82, 0.84, and 0.86.
* **Legend:** Located in the bottom-right corner.
* GRPO (Blue)
* MEL (Pink)
### Detailed Analysis
* **GRPO (Blue):**
* Trend: Generally increasing with fluctuations.
* Data Points:
* (0, 0.77)
* (20, 0.79)
* (40, 0.815)
* (50, 0.805)
* (60, 0.818)
* (70, 0.848)
* (80, 0.838)
* (90, 0.848)
* (100, 0.852)
* (120, 0.85)
* (130, 0.858)
* (140, 0.844)
* **MEL (Pink):**
* Trend: Generally increasing with fluctuations, peaking around training step 100.
* Data Points:
* (0, 0.77)
* (10, 0.812)
* (20, 0.808)
* (30, 0.844)
* (40, 0.848)
* (50, 0.838)
* (60, 0.84)
* (70, 0.854)
* (80, 0.848)
* (90, 0.858)
* (100, 0.864)
* (120, 0.854)
* (130, 0.856)
* (140, 0.864)
### Key Observations
* Both models start with the same validation score at training step 0.
* MEL generally outperforms GRPO until around training step 120, after which their performance becomes similar.
* Both models exhibit fluctuations in their validation scores throughout the training process.
### Interpretation
The chart illustrates the performance of two models, GRPO and MEL, on the MATH500 benchmark. The validation scores indicate how well each model generalizes to unseen data during training. MEL appears to have a slightly better initial learning curve and maintains a higher validation score for a significant portion of the training steps. However, towards the end of the training, the performance of the two models converges. The fluctuations in validation scores suggest that both models experience periods of overfitting or underfitting during training, which is common in machine learning. The data suggests that MEL might be a better choice for this particular benchmark, at least for the initial training phase.