TECHNICAL ASSET FINGERPRINT
e4db6b9d816425d77b458ec2
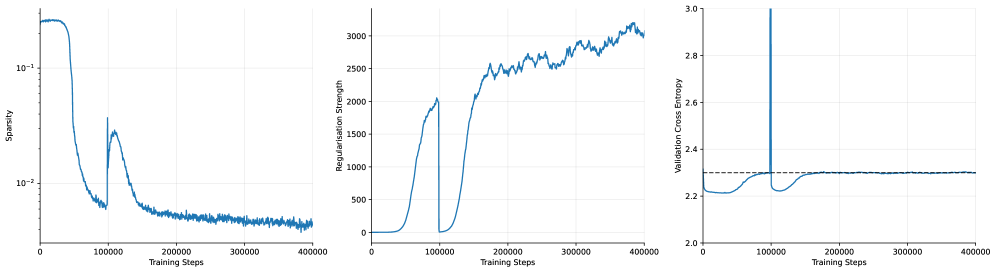
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
## Line Charts: Training Metrics
### Overview
The image presents three line charts displaying the training metrics of a model over 400,000 training steps. The charts depict Sparsity, Regularisation Strength, and Validation Cross Entropy. All three charts share the same x-axis: "Training Steps".
### Components/Axes
**Chart 1: Sparsity**
* **Y-axis:** Sparsity (log scale)
* Scale ranges from approximately 0.005 to 0.2.
* Markers at 10^-2 and 10^-1.
* **X-axis:** Training Steps
* Scale ranges from 0 to 400,000.
* Markers at 0, 100,000, 200,000, 300,000, and 400,000.
**Chart 2: Regularisation Strength**
* **Y-axis:** Regularisation Strength
* Scale ranges from 0 to 3000.
* Markers at 0, 500, 1000, 1500, 2000, 2500, and 3000.
* **X-axis:** Training Steps
* Scale ranges from 0 to 400,000.
* Markers at 0, 100,000, 200,000, 300,000, and 400,000.
**Chart 3: Validation Cross Entropy**
* **Y-axis:** Validation Cross Entropy
* Scale ranges from 2.0 to 3.0.
* Markers at 2.0, 2.2, 2.4, 2.6, 2.8, and 3.0.
* **X-axis:** Training Steps
* Scale ranges from 0 to 400,000.
* Markers at 0, 100,000, 200,000, 300,000, and 400,000.
* A dashed horizontal line is present at approximately y = 2.3.
### Detailed Analysis
**Chart 1: Sparsity**
* **Trend:** The sparsity starts high (around 0.2), rapidly decreases until approximately 80,000 training steps, then experiences a sharp increase around 100,000 steps, followed by a gradual decrease and stabilization around 0.005 for the remainder of the training.
* **Data Points:**
* Initial Sparsity: ~0.2
* Sparsity at 80,000 steps: ~0.006
* Peak after increase: ~0.03
* Final Sparsity: ~0.005
**Chart 2: Regularisation Strength**
* **Trend:** The regularisation strength starts at 0, remains low until around 50,000 training steps, then rapidly increases until approximately 100,000 steps, drops back to 0, then increases again until approximately 200,000 steps, and then continues to increase more gradually with some fluctuations until the end of training.
* **Data Points:**
* Initial Regularisation Strength: 0
* Regularisation Strength at 100,000 steps: ~2000
* Regularisation Strength at 200,000 steps: ~2000
* Final Regularisation Strength: ~3000
**Chart 3: Validation Cross Entropy**
* **Trend:** The validation cross entropy starts around 2.2, decreases slightly until approximately 50,000 training steps, then increases sharply until approximately 100,000 steps, followed by a decrease and stabilization around 2.3 for the remainder of the training.
* **Data Points:**
* Initial Validation Cross Entropy: ~2.2
* Minimum Validation Cross Entropy: ~2.2
* Peak after increase: ~2.3
* Final Validation Cross Entropy: ~2.3
### Key Observations
* All three metrics exhibit significant changes around 50,000-100,000 training steps.
* Sparsity and Regularisation Strength appear to be inversely related in the initial phase of training.
* Validation Cross Entropy stabilizes after the initial fluctuations.
### Interpretation
The charts suggest that the model undergoes a significant adjustment phase during the first 100,000 training steps. The initial decrease in sparsity corresponds to an increase in regularisation strength, indicating that the model is learning to prioritize important features. The subsequent increase in validation cross entropy suggests a potential overfitting issue, which is then corrected as the model continues to train and the validation cross entropy stabilizes. The dashed line on the Validation Cross Entropy chart likely represents a target or acceptable level of validation error. The model appears to achieve and maintain this level after the initial adjustment period.
DECODING INTELLIGENCE...
EXPERT: gemini-3.1-pro-preview VERSION 1
RUNTIME: gemini/gemini-3.1-pro-preview
INTEL_VERIFIED
## Line Charts: Training Metrics over Time (Sparsity, Regularisation Strength, Validation Cross Entropy)
### Overview
The image consists of three line charts arranged horizontally side-by-side. All three charts share an identical X-axis representing "Training Steps" from 0 to 400,000. The charts display the evolution of three distinct machine learning metrics during a training run. A highly notable, synchronized anomaly or intervention occurs across all three charts at exactly 100,000 training steps.
### Components/Axes
**Global X-Axis (Applies to all three charts):**
* **Label:** `Training Steps`
* **Scale:** Linear
* **Range:** 0 to 400,000
* **Major Markers:** 0, 100000, 200000, 300000, 400000
**Left Chart Y-Axis:**
* **Label:** `Sparsity`
* **Scale:** Logarithmic
* **Major Markers:** $10^{-2}$, $10^{-1}$ (Gridlines suggest minor ticks between these powers of 10)
**Middle Chart Y-Axis:**
* **Label:** `Regularisation Strength`
* **Scale:** Linear
* **Range:** 0 to slightly above 3000
* **Major Markers:** 0, 500, 1000, 1500, 2000, 2500, 3000
**Right Chart Y-Axis:**
* **Label:** `Validation Cross Entropy`
* **Scale:** Linear
* **Range:** 2.0 to 3.0
* **Major Markers:** 2.0, 2.2, 2.4, 2.6, 2.8, 3.0
* **Additional Element:** A horizontal dashed black line is present at exactly the 2.3 mark.
---
### Detailed Analysis
#### 1. Left Chart: Sparsity vs. Training Steps
* **Visual Trend:** The line begins at a high value, remains relatively flat, and then experiences a steep drop. It bottoms out just before the 100k mark. At exactly 100,000 steps, there is a sharp, instantaneous upward spike. Following the spike, the line forms a rounded local peak before gradually decaying with high-frequency noise (jitter) for the remainder of the training, ending at its lowest point.
* **Data Points (Approximate):**
* **Step 0 to ~30,000:** Starts flat at approximately $2 \times 10^{-1}$ (0.2).
* **Step ~30,000 to 99,999:** Drops sharply, reaching a local minimum of approximately $6 \times 10^{-3}$ (0.006).
* **Step 100,000:** Instantaneous spike up to approximately $3 \times 10^{-2}$ (0.03).
* **Step ~110,000:** Forms a local peak at approximately $2 \times 10^{-2}$ (0.02).
* **Step 150,000 to 400,000:** Gradual, noisy decay, ending at approximately $4 \times 10^{-3}$ (0.004) at step 400,000.
#### 2. Middle Chart: Regularisation Strength vs. Training Steps
* **Visual Trend:** The line starts at zero and remains flat. It then rises in a smooth S-curve (sigmoid-like) shape. At exactly 100,000 steps, it plummets instantaneously back to zero. It remains at zero briefly before initiating a second, much larger S-curve rise. This second rise becomes increasingly noisy and continues to trend upward until the end of the chart.
* **Data Points (Approximate):**
* **Step 0 to ~40,000:** Flat at 0.
* **Step ~40,000 to 99,999:** Rises steeply, peaking at approximately 2050.
* **Step 100,000:** Instantaneous drop to 0.
* **Step 100,000 to ~120,000:** Remains near 0.
* **Step ~120,000 to 400,000:** Rises steeply again, crossing the previous peak of 2000 around step 175,000. The line becomes noisy, reaching a maximum of approximately 3150 near step 380,000, and ends slightly lower at ~3000 at step 400,000.
#### 3. Right Chart: Validation Cross Entropy vs. Training Steps
* **Visual Trend:** The line starts near the dashed reference line, dips down to a minimum, and then slowly curves back up to meet the dashed line. At exactly 100,000 steps, there is a massive, instantaneous vertical spike that exceeds the upper bounds of the chart. Immediately after, it drops back down to a low value, and slowly curves back up, eventually asymptoting perfectly onto the horizontal dashed line for the entire second half of the training run.
* **Data Points (Approximate):**
* **Step 0:** Starts at approximately 2.3.
* **Step ~20,000 to 40,000:** Dips to a minimum of approximately 2.21.
* **Step ~40,000 to 99,999:** Rises smoothly, reaching exactly 2.3 (the dashed line) just before the 100k mark.
* **Step 100,000:** A massive spike that shoots vertically past the maximum Y-axis value of 3.0.
* **Step ~105,000:** Drops rapidly back down to approximately 2.22.
* **Step ~105,000 to 200,000:** Rises smoothly back toward the dashed line.
* **Step 200,000 to 400,000:** The line flattens out and tracks exactly on the dashed reference line at 2.3, with very minor noise.
---
### Key Observations
1. **The 100k Step Anomaly:** There is a highly coordinated event at exactly 100,000 training steps. Regularisation is turned off (drops to 0), Sparsity spikes upward, and Validation Cross Entropy experiences a massive, out-of-bounds spike.
2. **Correlated Curves:** The shape of the "Regularisation Strength" curve (Middle) is inversely correlated with the initial drop in "Sparsity" (Left) and directly correlated with the rise in "Validation Cross Entropy" (Right). When regularisation is 0, cross-entropy is at its lowest (~2.21). As regularisation increases, cross-entropy increases.
3. **The Dashed Target Line:** The dashed line at 2.3 on the rightmost chart acts as a hard ceiling or target. The system appears to increase regularisation *until* the validation cross-entropy hits 2.3, at which point it stops increasing the loss further.
### Interpretation
These charts depict a sophisticated, dynamic training curriculum for a machine learning model, likely involving automated network pruning or a sparsity-inducing penalty (such as L1 regularization).
* **Phase 1 (0 - 100k steps):** The model begins training normally. Around 40k steps, an automated controller begins applying a "Regularisation Strength" penalty. As this penalty increases, the model becomes less sparse (Sparsity drops from $10^{-1}$ to $10^{-2}$). However, this regularisation harms the model's performance, causing the Validation Cross Entropy (loss) to rise from its natural minimum of 2.21 up to a predefined tolerance threshold of 2.3.
* **The Intervention (100k steps):** At 100,000 steps, a hard reset or phase shift occurs. The regularisation penalty is instantly removed (drops to 0). This sudden change in the loss landscape causes a massive, temporary shock to the model's validation loss (the spike > 3.0). Simultaneously, the sparsity spikes, indicating a sudden change in the network's weights (perhaps a pruning mask was updated or weights were re-initialized).
* **Phase 2 (100k - 400k steps):** The model recovers quickly from the shock, and loss drops back down. The automated controller once again begins ramping up the Regularisation Strength. This time, it pushes the regularisation much higher (up to 3000 compared to the previous 2000). It continues to push this penalty higher and higher, driving Sparsity down to its absolute minimum ($~4 \times 10^{-3}$), while perfectly balancing the Validation Cross Entropy exactly on the maximum allowed threshold of 2.3.
**Conclusion:** The data demonstrates an algorithm designed to maximize regularisation (and thereby minimize sparsity) *subject to the constraint* that validation loss must not exceed 2.3. The event at 100k steps was likely a programmed curriculum shift to allow the model to escape a local minimum and find a state where it could accept even higher regularisation while maintaining the target loss.
DECODING INTELLIGENCE...
EXPERT: nemotron-free VERSION 1
RUNTIME: free/nvidia/nemotron-nano-12b-v2-vl:free
INTEL_VERIFIED
## Line Graphs: Training Metrics Over Steps
### Overview
The image contains three line graphs depicting training metrics across 400,000 training steps. Each graph tracks a distinct metric: sparsity, regularization strength, and validation cross entropy. All graphs share the same x-axis (training steps) but have unique y-axes and trends.
---
### Components/Axes
1. **Left Graph (Sparsity)**
- **Y-axis**: "Sparsity" (logarithmic scale: 10⁻¹ to 10⁻²)
- **X-axis**: "Training Steps" (0 to 400,000)
- **Line**: Blue, single data series.
2. **Middle Graph (Regularisation Strength)**
- **Y-axis**: "Regularisation Strength" (linear scale: 0 to 3,000)
- **X-axis**: "Training Steps" (0 to 400,000)
- **Line**: Blue, single data series.
3. **Right Graph (Validation Cross Entropy)**
- **Y-axis**: "Validation Cross Entropy" (linear scale: 2.0 to 3.0)
- **X-axis**: "Training Steps" (0 to 400,000)
- **Line**: Blue, single data series.
- **Dashed Line**: Horizontal reference at ~2.4.
---
### Detailed Analysis
#### Left Graph (Sparsity)
- **Initial Drop**: Sparsity plunges from ~10⁻¹ to ~10⁻² within ~50,000 steps.
- **Secondary Peak**: A sharp spike to ~10⁻¹ occurs at ~100,000 steps, followed by a rapid decline.
- **Stabilization**: Settles near ~10⁻² between 200,000 and 400,000 steps.
#### Middle Graph (Regularisation Strength)
- **Initial Rise**: Gradual increase from 0 to ~1,500 by ~100,000 steps.
- **Sharp Drop**: Plummets to ~0 at ~100,000 steps.
- **Secondary Rise**: Peaks at ~2,500 around 200,000 steps, then fluctuates between 2,000–2,500 until 400,000 steps.
#### Right Graph (Validation Cross Entropy)
- **Initial Stability**: Remains near 2.2 until ~100,000 steps.
- **Sharp Spike**: Jumps to ~2.8 at ~100,000 steps, then drops back to ~2.2.
- **Final Stability**: Fluctuates slightly (~2.2–2.3) but remains stable after 200,000 steps.
- **Dashed Line**: Horizontal reference at ~2.4, indicating a target or threshold.
---
### Key Observations
1. **Sparsity**: Initial high sparsity drops sharply, with a brief rebound at 100k steps before stabilizing.
2. **Regularisation Strength**: Two distinct phases—initial growth, abrupt reset, then gradual increase with fluctuations.
3. **Validation Cross Entropy**: A single catastrophic spike at 100k steps, followed by recovery and stability.
4. **Dashed Line**: The ~2.4 threshold in the right graph is never consistently met, suggesting suboptimal validation performance.
---
### Interpretation
- **Sparsity & Regularisation**: The sharp drop in sparsity and regularisation strength at 100k steps suggests a major model adjustment (e.g., weight pruning or hyperparameter tuning). The subsequent rise in regularisation strength may indicate rebalancing to prevent overfitting.
- **Validation Cross Entropy Spike**: The 100k-step spike in validation error implies overfitting or instability during model adjustment. The recovery afterward suggests the model stabilized post-adjustment.
- **Dashed Line Significance**: The ~2.4 threshold likely represents a target validation error. The model’s inability to sustainably meet this threshold indicates room for improvement in regularisation or architecture.
- **Correlation**: The synchronization of spikes in sparsity, regularisation, and validation error at 100k steps implies a coordinated training intervention (e.g., learning rate change or layer freezing).
The data highlights critical phases in training dynamics, emphasizing the interplay between model complexity (sparsity), regularisation, and validation performance.
DECODING INTELLIGENCE...