\n
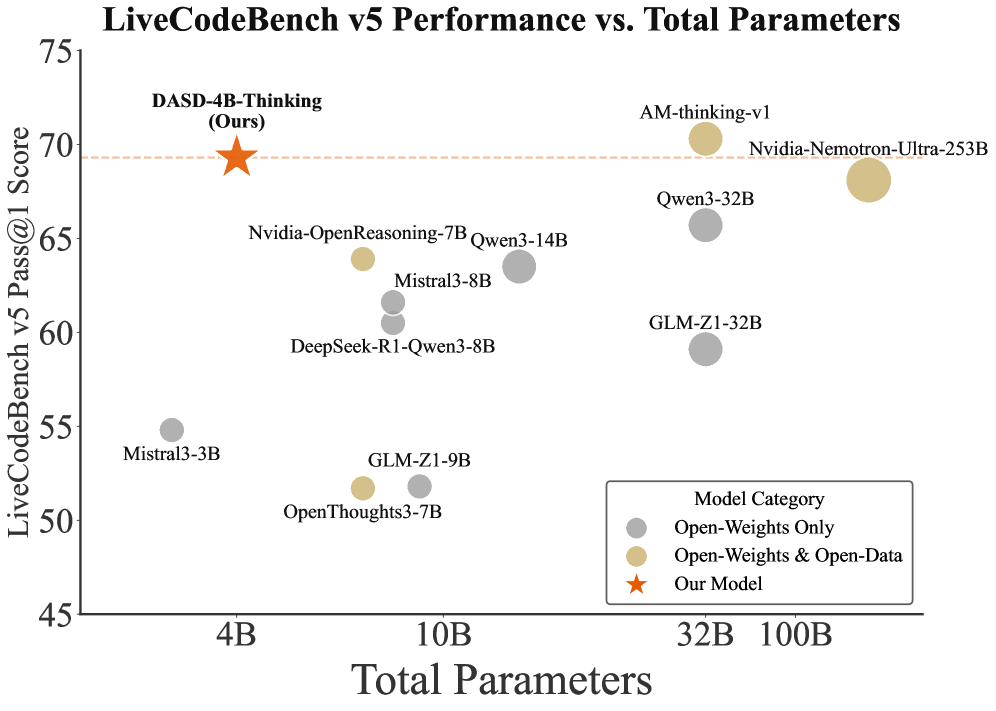
## Scatter Plot: LiveCodeBench v5 Performance vs. Total Parameters
### Overview
This scatter plot visualizes the relationship between the LiveCodeBench v5 Pass@1 Score and the Total Parameters of various language models. The plot includes data points representing different models, categorized by their openness (Open-Weights Only, Open-Weights & Open-Data, and Our Model).
### Components/Axes
* **Title:** LiveCodeBench v5 Performance vs. Total Parameters
* **X-axis:** Total Parameters (Scale: 4B to 100B, with markers at 4B, 10B, 32B, and 100B)
* **Y-axis:** LiveCodeBench v5 Pass@1 Score (Scale: 45 to 75, with markers at 45, 50, 55, 60, 65, 70, and 75)
* **Legend:** Located in the bottom-right corner.
* Gray Circles: Open-Weights Only
* Yellow Circles: Open-Weights & Open-Data
* Orange Star: Our Model
### Detailed Analysis
The plot displays the following data points. Note that values are approximate due to visual estimation.
* **DASD-4B-Thinking (Ours):** Approximately (4B, 70.5). Represented by an orange star.
* **AM-thinking-v1:** Approximately (100B, 70). Represented by a yellow circle.
* **Nvidia-Nemotron-Ultra-253B:** Approximately (100B, 69). Represented by a yellow circle.
* **Qwen-32B:** Approximately (32B, 67). Represented by a gray circle.
* **Nvidia-OpenReasoning-7B:** Approximately (10B, 66). Represented by a gray circle.
* **Qwen3-14B:** Approximately (14B, 66). Represented by a gray circle.
* **GLM-Z1-32B:** Approximately (32B, 64). Represented by a gray circle.
* **Mistral3-8B:** Approximately (8B, 64). Represented by a gray circle.
* **DeepSeek-R1-Qwen3-8B:** Approximately (8B, 60). Represented by a gray circle.
* **GLM-Z1-9B:** Approximately (9B, 59). Represented by a gray circle.
* **OpenThoughts3-7B:** Approximately (7B, 52). Represented by a gray circle.
* **Mistral3-3B:** Approximately (3B, 55). Represented by a gray circle.
**Trends:**
* Generally, as the number of Total Parameters increases, the LiveCodeBench v5 Pass@1 Score tends to increase, but this is not a strict correlation.
* The "Our Model" (DASD-4B-Thinking) achieves a relatively high score (approximately 70.5) with a comparatively small number of parameters (4B).
* Models with 32B and 100B parameters show a range of scores, indicating that parameter count alone does not determine performance.
### Key Observations
* The "Our Model" (DASD-4B-Thinking) appears to be an outlier, achieving a high score with a relatively low parameter count.
* There is significant variance in performance among models with similar parameter counts (e.g., the 32B models).
* The highest parameter count models (100B) do not necessarily have the highest scores.
### Interpretation
The data suggests that model performance on the LiveCodeBench v5 benchmark is not solely determined by the number of parameters. Model architecture, training data, and other factors likely play a significant role. The "Our Model" (DASD-4B-Thinking) demonstrates that a well-designed model can achieve competitive performance with fewer parameters, potentially offering advantages in terms of computational cost and efficiency. The scatterplot highlights the importance of evaluating models based on performance metrics rather than solely relying on parameter count as an indicator of capability. The spread of data points indicates that there is no simple linear relationship between parameters and performance, and further investigation is needed to understand the underlying factors driving these differences.