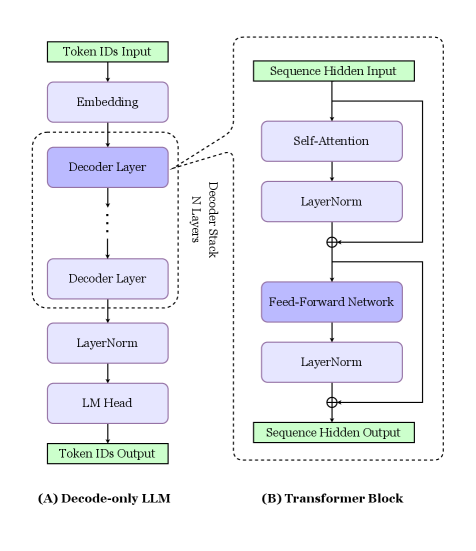
## Diagram: Neural Network Architectures Comparison
### Overview
The image compares two neural network architectures: **(A) Decode-only LLM** and **(B) Transformer Block**. Both are depicted as sequential processing pipelines with labeled components and directional flow.
### Components/Axes
#### (A) Decode-only LLM
1. **Token IDs Input** → **Embedding** → **Decoder Layer** (stacked N times) → **LayerNorm** → **LM Head** → **Token IDs Output**
2. **Decoder Stack**: Explicitly labeled as containing "N Layers," indicating variable depth.
3. **Flow**: Vertical progression from input to output, with residual connections implied by dashed arrows between decoder layers.
#### (B) Transformer Block
1. **Sequence Hidden Input** → **Self-Attention** → **LayerNorm** → **Feed-Forward Network** → **LayerNorm** → **Sequence Hidden Output**
2. **Dual Pathway**: Self-Attention and Feed-Forward Network are isolated sub-blocks with shared LayerNorm steps.
3. **Flow**: Vertical progression with parallel processing in the Self-Attention and Feed-Forward Network.
### Content Details
- **Labels**: All components are explicitly labeled (e.g., "Self-Attention," "Feed-Forward Network").
- **Arrows**: Dashed arrows indicate residual connections in (A); solid arrows denote direct flow in (B).
- **Normalization**: LayerNorm appears in both architectures but is positioned differently (after decoder layers in A, after attention/FFN in B).
- **Outputs**: (A) produces **Token IDs Output**; (B) produces **Sequence Hidden Output**.
### Key Observations
1. **Architectural Focus**:
- (A) emphasizes **decoder-only processing** for autoregressive tasks (e.g., text generation).
- (B) highlights **transformer mechanics** (attention + FFN) for sequence modeling.
2. **LayerStack Flexibility**: The "N Layers" in (A) suggests scalability, while (B) uses fixed sub-blocks.
3. **Normalization Placement**: LayerNorm in (A) follows decoder layers, whereas in (B) it follows attention and FFN.
### Interpretation
- **Decode-only LLM (A)**: Optimized for tasks requiring sequential token generation (e.g., GPT-style models). The residual connections (dashed arrows) enable deeper networks without vanishing gradients.
- **Transformer Block (B)**: Represents a core building block of encoder-decoder models (e.g., BERT, T5). The separation of Self-Attention and Feed-Forward Network allows parallel computation and modular design.
- **Shared Mechanisms**: Both use LayerNorm for stability, but its placement reflects architectural priorities (post-decoding vs. post-attention).
This diagram illustrates how different neural network designs balance computational efficiency, scalability, and task-specific optimizations.