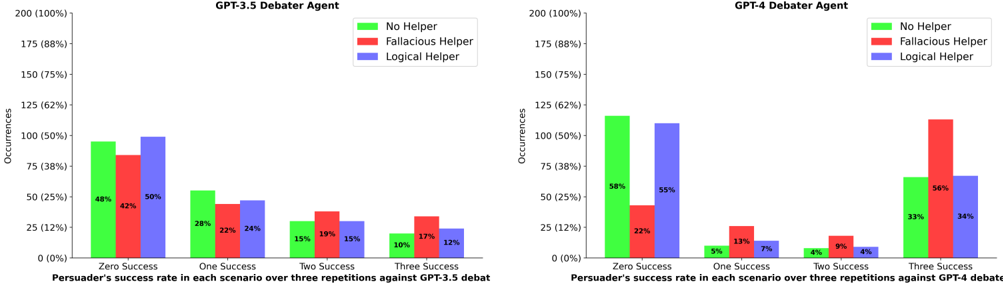
## Bar Chart: Persuader's Success Rate with Different Helpers
### Overview
The image presents two bar charts comparing the persuader's success rate in debates against GPT-3.5 and GPT-4, respectively. The success rate is evaluated across scenarios with varying numbers of successful repetitions (Zero, One, Two, Three), and the charts compare the impact of using "No Helper," a "Fallacious Helper," and a "Logical Helper."
### Components/Axes
**Left Chart (GPT-3.5 Debater Agent):**
* **Title:** GPT-3.5 Debater Agent
* **Y-axis:** Occurrences, with scale markers at 0 (0%), 25 (12%), 50 (25%), 75 (38%), 100 (50%), 125 (62%), 150 (75%), 175 (88%), and 200 (100%).
* **X-axis:** Persuader's success rate in each scenario over three repetitions against GPT-3.5 debat. Categories are "Zero Success", "One Success", "Two Success", and "Three Success".
* **Legend:** Located at the top-right of the chart.
* Green: No Helper
* Red: Fallacious Helper
* Blue: Logical Helper
**Right Chart (GPT-4 Debater Agent):**
* **Title:** GPT-4 Debater Agent
* **Y-axis:** Occurrences, with scale markers at 0 (0%), 25 (12%), 50 (25%), 75 (38%), 100 (50%), 125 (62%), 150 (75%), 175 (88%), and 200 (100%).
* **X-axis:** Persuader's success rate in each scenario over three repetitions against GPT-4 debate. Categories are "Zero Success", "One Success", "Two Success", and "Three Success".
* **Legend:** Located at the top-right of the chart.
* Green: No Helper
* Red: Fallacious Helper
* Blue: Logical Helper
### Detailed Analysis
**GPT-3.5 Debater Agent Chart:**
* **Zero Success:**
* No Helper (Green): Approximately 48%
* Fallacious Helper (Red): Approximately 42%
* Logical Helper (Blue): Approximately 50%
* **One Success:**
* No Helper (Green): Approximately 28%
* Fallacious Helper (Red): Approximately 22%
* Logical Helper (Blue): Approximately 24%
* **Two Success:**
* No Helper (Green): Approximately 15%
* Fallacious Helper (Red): Approximately 19%
* Logical Helper (Blue): Approximately 15%
* **Three Success:**
* No Helper (Green): Approximately 10%
* Fallacious Helper (Red): Approximately 17%
* Logical Helper (Blue): Approximately 12%
**GPT-4 Debater Agent Chart:**
* **Zero Success:**
* No Helper (Green): Approximately 58%
* Fallacious Helper (Red): Approximately 22%
* Logical Helper (Blue): Approximately 55%
* **One Success:**
* No Helper (Green): Approximately 5%
* Fallacious Helper (Red): Approximately 13%
* Logical Helper (Blue): Approximately 7%
* **Two Success:**
* No Helper (Green): Approximately 4%
* Fallacious Helper (Red): Approximately 9%
* Logical Helper (Blue): Approximately 4%
* **Three Success:**
* No Helper (Green): Approximately 33%
* Fallacious Helper (Red): Approximately 56%
* Logical Helper (Blue): Approximately 34%
### Key Observations
* **GPT-3.5:** For GPT-3.5, the "Logical Helper" shows a slightly higher success rate in the "Zero Success" category compared to "No Helper" and "Fallacious Helper." The success rates decrease as the number of successful repetitions increases for all helper types.
* **GPT-4:** For GPT-4, the "Fallacious Helper" has a significantly higher success rate in the "Three Success" category compared to "No Helper" and "Logical Helper." The "No Helper" scenario has the highest success rate in the "Zero Success" category.
### Interpretation
The charts illustrate the impact of different types of helpers on the persuader's success rate against GPT-3.5 and GPT-4 debater agents. The data suggests that the effectiveness of a helper depends on the specific AI model being debated against and the desired outcome (number of successful repetitions).
* **GPT-3.5:** A logical helper seems to provide a slight advantage when the goal is to achieve at least some level of success (Zero Success).
* **GPT-4:** A fallacious helper is surprisingly effective when the goal is to achieve a high number of successful repetitions (Three Success). This could indicate that GPT-4 is more susceptible to flawed reasoning or that a fallacious argument is more persuasive in certain contexts. The "No Helper" condition performs best when no successes are needed.
The data highlights the nuanced relationship between AI models, argumentation strategies, and the role of helpers in debates. It suggests that the optimal strategy for persuasion may vary depending on the specific AI model being targeted.