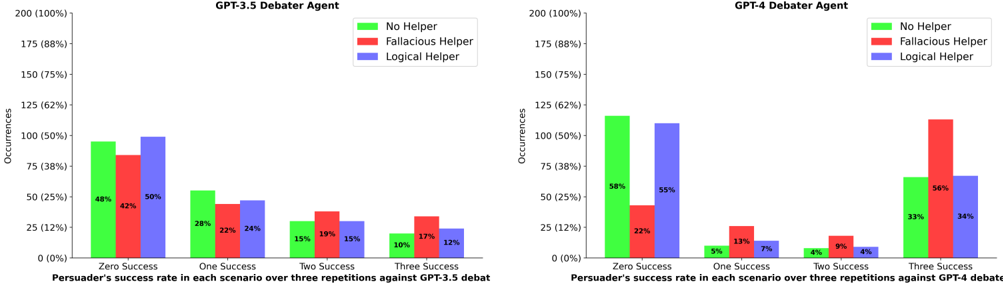
## Bar Chart: Persuader Success Rate vs. Helper Type
### Overview
The image presents two side-by-side bar charts comparing the success rate of a "Persuader" against GPT-3.5 and GPT-4 in a debate scenario. The charts show the distribution of "Occurrences" across different levels of success (Zero, One, Two, Three) for each type of "Helper" (No Helper, Fallacious Helper, Logical Helper). The x-axis represents the success levels, and the y-axis represents the number of occurrences, expressed as both a count and a percentage.
### Components/Axes
* **Title (Left Chart):** "GPT-3.5 Debater Agent"
* **Title (Right Chart):** "GPT-4 Debater Agent"
* **X-axis Label:** "Persuader's success rate in each scenario over three repetitions against GPT-3.5 debate" (Left Chart) / "Persuader's success rate in each scenario over three repetitions against GPT-4 debate" (Right Chart)
* **Y-axis Label:** "Occurrences" (with scale from 0 to 200, also showing percentage equivalents: 0% to 100%)
* **Legend:**
* Green: "No Helper"
* Red: "Fallacious Helper"
* Blue: "Logical Helper"
* **X-axis Markers:** "Zero Success", "One Success", "Two Success", "Three Success"
### Detailed Analysis or Content Details
**Left Chart (GPT-3.5):**
* **No Helper (Green):**
* Zero Success: Approximately 48% (96 occurrences)
* One Success: Approximately 50% (100 occurrences)
* Two Success: Approximately 22% (44 occurrences)
* Three Success: Approximately 17% (34 occurrences)
* **Fallacious Helper (Red):**
* Zero Success: Approximately 42% (84 occurrences)
* One Success: Approximately 28% (56 occurrences)
* Two Success: Approximately 15% (30 occurrences)
* Three Success: Approximately 10% (20 occurrences)
* **Logical Helper (Blue):**
* Zero Success: Approximately 50% (100 occurrences)
* One Success: Approximately 24% (48 occurrences)
* Two Success: Approximately 19% (38 occurrences)
* Three Success: Approximately 12% (24 occurrences)
**Right Chart (GPT-4):**
* **No Helper (Green):**
* Zero Success: Approximately 58% (116 occurrences)
* One Success: Approximately 22% (44 occurrences)
* Two Success: Approximately 4% (8 occurrences)
* Three Success: Approximately 33% (66 occurrences)
* **Fallacious Helper (Red):**
* Zero Success: Approximately 55% (110 occurrences)
* One Success: Approximately 13% (26 occurrences)
* Two Success: Approximately 7% (14 occurrences)
* Three Success: Approximately 56% (112 occurrences)
* **Logical Helper (Blue):**
* Zero Success: Approximately 34% (68 occurrences)
* One Success: Approximately 34% (68 occurrences)
* Two Success: Approximately 9% (18 occurrences)
* Three Success: Approximately 34% (68 occurrences)
### Key Observations
* **GPT-3.5:** The "No Helper" and "Logical Helper" scenarios show similar distributions, with a peak at "Zero Success" and "One Success". The "Fallacious Helper" consistently results in lower occurrences at "Zero Success" and higher occurrences at lower success levels.
* **GPT-4:** The "No Helper" scenario has a high occurrence at "Zero Success". The "Fallacious Helper" shows a significant peak at "Three Success", indicating it may be surprisingly effective in some cases. The "Logical Helper" shows a more even distribution across all success levels.
* **Comparison:** GPT-4 appears to be more resistant to the "No Helper" scenario, with a higher percentage of "Three Success" outcomes compared to GPT-3.5. The "Fallacious Helper" seems to have a more pronounced effect on GPT-4, leading to a higher success rate in some scenarios.
### Interpretation
The data suggests that the type of "Helper" used significantly impacts the Persuader's success rate in debates against both GPT-3.5 and GPT-4. The "Fallacious Helper" appears to be counterintuitively effective against GPT-4, potentially because GPT-4 attempts to address the fallacies directly, giving the persuader an opening. The "Logical Helper" doesn't consistently improve the Persuader's success rate against GPT-3.5, suggesting that simply providing logical arguments isn't enough to overcome GPT-3.5's debating capabilities. GPT-4 demonstrates greater resilience to the "No Helper" scenario, indicating an improved ability to defend against unassisted persuasion attempts. The differences in the distributions between the two models highlight the advancements in reasoning and debate skills between GPT-3.5 and GPT-4. The data also suggests that the nature of the debate and the specific fallacies employed could play a crucial role in determining the outcome.