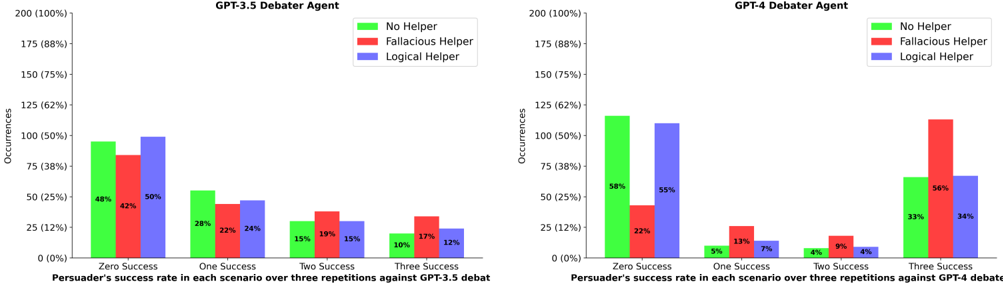
## Bar Charts: Persuader Success Rates with Different Helper Agents
### Overview
The image contains two side-by-side bar charts comparing the success rates of persuaders against GPT-3.5 and GPT-4 debater agents across three helper scenarios: No Helper, Fallacious Helper, and Logical Helper. Each chart shows occurrences (in percentages) for persuader success rates categorized as Zero, One, Two, or Three Successes over three debate repetitions.
---
### Components/Axes
**Left Chart (GPT-3.5 Debater Agent):**
- **X-Axis**: Persuader's success rate categories:
- Zero Success
- One Success
- Two Success
- Three Success
- **Y-Axis**: Occurrences (0% to 200%, labeled as percentages)
- **Legend**:
- Green: No Helper
- Red: Fallacious Helper
- Blue: Logical Helper
- **Title**: "GPT-3.5 Debater Agent" (top-center)
**Right Chart (GPT-4 Debater Agent):**
- Identical structure to the left chart but with different numerical values.
- **Title**: "GPT-4 Debater Agent" (top-center)
**Spatial Grounding**:
- Legends are positioned in the top-right corner of each chart.
- Bars are clustered by helper type (green/red/blue) within each success category.
---
### Detailed Analysis
**GPT-3.5 Debater Agent (Left Chart):**
- **Zero Success**:
- No Helper: 48%
- Fallacious Helper: 42%
- Logical Helper: 50%
- **One Success**:
- No Helper: 28%
- Fallacious Helper: 22%
- Logical Helper: 24%
- **Two Success**:
- No Helper: 15%
- Fallacious Helper: 19%
- Logical Helper: 15%
- **Three Success**:
- No Helper: 10%
- Fallacious Helper: 17%
- Logical Helper: 12%
**GPT-4 Debater Agent (Right Chart):**
- **Zero Success**:
- No Helper: 58%
- Fallacious Helper: 22%
- Logical Helper: 55%
- **One Success**:
- No Helper: 5%
- Fallacious Helper: 13%
- Logical Helper: 7%
- **Two Success**:
- No Helper: 4%
- Fallacious Helper: 9%
- Logical Helper: 4%
- **Three Success**:
- No Helper: 33%
- Fallacious Helper: 56%
- Logical Helper: 34%
---
### Key Observations
1. **GPT-3.5 Trends**:
- Logical Helpers show the highest success in Zero Success (50%) but decline sharply in higher success categories.
- Fallacious Helpers outperform others in Three Success (17%).
- No Helper performs moderately across all categories.
2. **GPT-4 Trends**:
- Logical Helpers dominate Zero Success (55%) but underperform in higher success categories.
- Fallacious Helpers achieve the highest Three Success rate (56%), significantly outperforming others.
- No Helper shows inconsistent performance, peaking at Zero Success (58%) but dropping to 4% in Two Success.
3. **Cross-Model Comparison**:
- GPT-4 shows a stronger correlation between Fallacious Helpers and high persuader success (56% vs. GPT-3.5's 17%).
- Logical Helpers underperform in GPT-4's Three Success category (34% vs. Fallacious 56%).
---
### Interpretation
The data suggests that **Fallacious Helper agents** are disproportionately effective in scenarios where persuaders achieve high success rates (e.g., Three Success), particularly against GPT-4. This could indicate that fallacious reasoning exploits weaknesses in GPT-4's debate strategy. Conversely, **Logical Helpers** perform best in low-success scenarios (Zero Success) but struggle to maintain effectiveness in high-stakes debates. The **No Helper** baseline shows mixed results, suggesting that helper agents generally improve persuader performance, but their impact varies by model and helper type.
Notably, the stark contrast in GPT-4's Three Success rates (Fallacious 56% vs. Logical 34%) raises questions about the robustness of logical reasoning frameworks against adversarial tactics. This aligns with broader AI safety concerns about deceptive alignment in language models.