## Diagram: Combo Premonition Analysis
### Overview
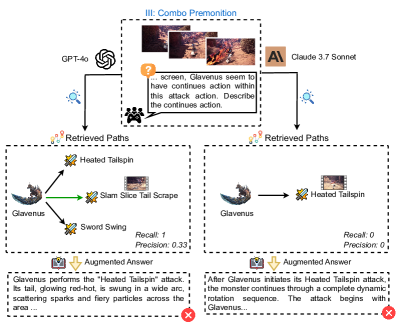
The image presents a diagram illustrating a "Combo Premonition" analysis, comparing the outputs of two AI models (GPT-4o and Claude 3.7 Sonnet) in predicting the continuation of an attack action by a character named Glavenus. The diagram shows the retrieved paths and augmented answers generated by each model, along with recall and precision metrics.
### Components/Axes
* **Title:** III: Combo Premonition
* **Top-Left:** GPT-4o (AI Model)
* **Top-Right:** Claude 3.7 Sonnet (AI Model)
* **Center:**
* A question mark icon.
* Text: "... screen, Glavenus seem to have continues action within this attack action. Describe the continues action."
* A group of player icons.
* **Left Side:**
* "Retrieved Paths" label with icons.
* Nodes: Glavenus, Heated Tailspin, Slam Slice Tail Scrape, Sword Swing.
* Arrows indicating the sequence of actions.
* "Recall: 1"
* "Precision: 0.33"
* "Augmented Answer" label with icon.
* Text: "Glavenus performs the "Heated Tailspin" attack. Its tail, glowing red-hot, is swung in a wide arc, scattering sparks and fiery particles across the area..."
* Red "X" icon.
* **Right Side:**
* "Retrieved Paths" label with icons.
* Nodes: Glavenus, Heated Tailspin.
* Arrow indicating the sequence of actions.
* "Recall: 0"
* "Precision: 0"
* "Augmented Answer" label with icon.
* Text: "After Glavenus initiates its Heated Tailspin attack, the monster continues through a complete dynamic rotation sequence. The attack begins with Glavenus..."
* Red "X" icon.
### Detailed Analysis
**GPT-4o Branch (Left Side):**
* **Retrieved Paths:** The diagram shows Glavenus initiating an attack, followed by "Heated Tailspin," then a choice between "Slam Slice Tail Scrape" and "Sword Swing."
* **Recall:** 1
* **Precision:** 0.33
* **Augmented Answer:** The text describes Glavenus performing the "Heated Tailspin" attack, detailing the visual effects.
**Claude 3.7 Sonnet Branch (Right Side):**
* **Retrieved Paths:** The diagram shows Glavenus initiating an attack, followed only by "Heated Tailspin."
* **Recall:** 0
* **Precision:** 0
* **Augmented Answer:** The text describes Glavenus initiating the "Heated Tailspin" attack and continuing through a dynamic rotation sequence.
**Central Question:**
* The central question prompts the AI models to describe the continuation of an attack action by Glavenus.
### Key Observations
* GPT-4o identifies a more complex sequence of actions following the initial attack, while Claude 3.7 Sonnet only identifies the "Heated Tailspin."
* GPT-4o has a higher recall (1) and precision (0.33) compared to Claude 3.7 Sonnet (recall 0, precision 0).
* Both models' augmented answers describe the "Heated Tailspin" attack, but GPT-4o provides more detail.
* Both augmented answers are marked with a red "X", indicating a negative evaluation.
### Interpretation
The diagram illustrates a comparison of two AI models in predicting the continuation of an attack action. GPT-4o demonstrates a better understanding of the potential attack sequences, as indicated by its higher recall and precision. However, the red "X" icons suggest that both models' augmented answers are considered unsatisfactory, despite GPT-4o's more comprehensive prediction. This could be due to inaccuracies in the descriptions or a failure to fully capture the nuances of the attack sequence. The diagram highlights the challenges in accurately predicting and describing complex actions, even with advanced AI models.