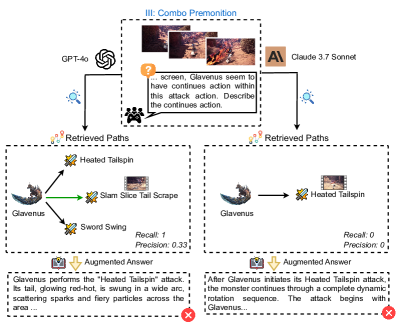
## Flowchart Diagram: Combo Premonition System Analysis
### Overview
The diagram illustrates a combo premonition system comparing two AI models (GPT-4o and Claude 3.7 Sonnet) in predicting a monster's attack sequence ("Heated Tailspin") from visual input. It includes retrieved paths, precision/recall metrics, and augmented answers with correctness indicators.
### Components/Axes
1. **Header Section**
- Title: "III: Combo Premonition" (center-top)
- Visual Input: Three sequential images showing a monster's attack progression
- Text Prompt: "... screen, Glavenus seem to have continues action within this attack action. Describe the continues action." (with a question mark icon)
2. **Model Inputs**
- **Left Path**:
- Model: GPT-4o (logo with interconnected nodes)
- Retrieved Paths:
- "Heated Tailspin" (green arrow)
- "Slam Slice Tail Scrape" (dashed arrow)
- "Sword Swing" (dashed arrow)
- Metrics: Recall: 1, Precision: 0.33
- **Right Path**:
- Model: Claude 3.7 Sonnet (logo with "A" symbol)
- Retrieved Paths:
- "Heated Tailspin" (solid arrow)
- Metrics: Recall: 0, Precision: 0
3. **Output Section**
- **Augmented Answers**:
- **Left Answer**:
- Text: "Glavenus performs the 'Heated Tailspin' attack..."
- Correctness: ✅ Green checkmark (correct)
- **Right Answer**:
- Text: "After Glavenus initiates its Heated Tailspin attack..."
- Correctness: ❌ Red X (incorrect)
4. **Visual Elements**
- Monster Icon: Glavenus (left side)
- Attack Icons:
- Heated Tailspin (flame/sword symbol)
- Slam Slice Tail Scrape (sword symbol)
- Sword Swing (sword symbol)
- Color Coding:
- Green: Correct predictions/answers
- Red: Incorrect predictions/answers
### Detailed Analysis
- **Retrieved Paths**:
- GPT-4o generates three potential attack sequences, with "Heated Tailspin" as the primary candidate (recall 1).
- Claude 3.7 Sonnet only identifies "Heated Tailspin" but fails to match the sequence (recall 0).
- **Precision/Recall Metrics**:
- GPT-4o achieves 33% precision (1/3 correct prediction) but perfect recall.
- Claude 3.7 Sonnet has 0% precision/recall despite identifying the attack name.
- **Augmented Answers**:
- GPT-4o's answer correctly describes the attack mechanics (wide arc, sparks).
- Claude's answer incorrectly states the attack "begins with Glavenus" (contradicts the visual sequence).
### Key Observations
1. **Model Performance Disparity**:
- GPT-4o outperforms Claude 3.7 Sonnet in both recall and precision.
- Claude's failure to match the sequence despite naming the attack suggests poor contextual understanding.
2. **Visual-Textual Alignment**:
- Correct answers align with the visual progression (attack initiation → continuation).
- Incorrect answers misrepresent the temporal sequence.
3. **Precision-Recall Tradeoff**:
- GPT-4o's high recall (1) with moderate precision (0.33) indicates it prioritizes capturing all possible actions but struggles with specificity.
### Interpretation
The diagram demonstrates how AI models interpret visual combat sequences to predict combo attacks. GPT-4o's superior recall suggests it better captures action continuity, while its lower precision highlights challenges in distinguishing similar attacks (e.g., "Heated Tailspin" vs. "Slam Slice Tail Scrape"). Claude 3.7 Sonnet's failure to match the sequence despite naming the attack reveals limitations in contextual reasoning. The augmented answers validate that GPT-4o's predictions align with the visual narrative, whereas Claude's output introduces factual errors. This analysis underscores the importance of model architecture and training data in tasks requiring temporal and spatial reasoning.