## Bar Chart: Percentage of Answers Considered Safe by Different AI Models
### Overview
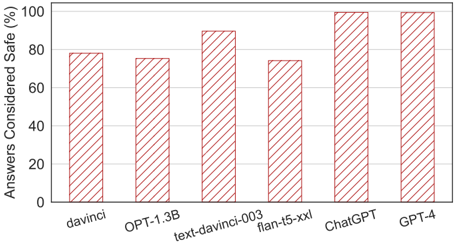
The chart compares the percentage of answers deemed "safe" by six AI models: davinci, OPT-1.3B, text-davinci-003, flan-t5-xxl, ChatGPT, and GPT-4. Safety is measured as the proportion of responses evaluated as safe, with values ranging from 0% to 100%.
### Components/Axes
- **X-axis**: AI model names (davinci, OPT-1.3B, text-davinci-003, flan-t5-xxl, ChatGPT, GPT-4), evenly spaced.
- **Y-axis**: "Answers Considered Safe (%)" with ticks at 0, 20, 40, 60, 80, 100.
- **Legend**: Located on the right, associating red diagonal stripes with the models (no explicit color coding per model; all bars share the same pattern).
- **Title**: "Percentage of Answers Considered Safe by Different AI Models" (top-center).
### Detailed Analysis
- **davinci**: ~78% (red striped bar, second from left).
- **OPT-1.3B**: ~75% (red striped bar, third from left).
- **text-davinci-003**: ~90% (red striped bar, fourth from left).
- **flan-t5-xxl**: ~72% (red striped bar, fifth from left).
- **ChatGPT**: ~100% (red striped bar, sixth from left).
- **GPT-4**: ~100% (red striped bar, far right).
### Key Observations
1. **Highest Safety**: ChatGPT and GPT-4 achieve 100% safety ratings, indicating near-perfect performance in this metric.
2. **Mid-Range Performance**: text-davinci-003 (~90%) outperforms older models like davinci (~78%) and OPT-1.3B (~75%).
3. **Lowest Safety**: flan-t5-xxl (~72%) has the lowest rating among the models.
4. **Trend**: Newer/generative models (ChatGPT, GPT-4) dominate in safety, while older or specialized models (flan-t5-xxl) lag.
### Interpretation
The data suggests a correlation between model architecture and perceived safety. ChatGPT and GPT-4, as advanced generative models, likely incorporate robust safety mechanisms, resulting in higher ratings. text-davinci-003’s strong performance (~90%) may reflect iterative improvements over earlier models like davinci. flan-t5-xxl’s lower score (~72%) could indicate challenges in handling safety-critical tasks despite its specialization. The uniformity of red striped bars implies a standardized evaluation framework across models. However, the absence of explicit error bars or confidence intervals limits conclusions about statistical significance. This chart highlights the importance of model design in ensuring safe AI interactions, with newer models setting a benchmark for reliability.