## Bar Chart: Answers Considered Safe by Model
### Overview
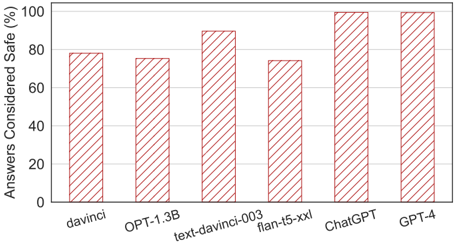
The image is a bar chart comparing the percentage of answers considered safe from different language models. The x-axis represents the language models, and the y-axis represents the percentage of answers considered safe.
### Components/Axes
* **X-axis:** Language Models (davinci, OPT-1.3B, text-davinci-003, flan-t5-xxl, ChatGPT, GPT-4)
* **Y-axis:** Answers Considered Safe (%) with scale from 0 to 100 in increments of 20.
* **Bars:** Each bar represents a language model, with the height indicating the percentage of answers considered safe. The bars are a reddish-brown color with diagonal lines filling the interior.
### Detailed Analysis
* **davinci:** Approximately 78% of answers considered safe.
* **OPT-1.3B:** Approximately 78% of answers considered safe.
* **text-davinci-003:** Approximately 90% of answers considered safe.
* **flan-t5-xxl:** Approximately 74% of answers considered safe.
* **ChatGPT:** Approximately 98% of answers considered safe.
* **GPT-4:** Approximately 96% of answers considered safe.
### Key Observations
* ChatGPT and GPT-4 have the highest percentage of answers considered safe.
* flan-t5-xxl has the lowest percentage of answers considered safe.
* There is a significant difference in safety between the older models (davinci, OPT-1.3B, text-davinci-003, flan-t5-xxl) and the newer models (ChatGPT, GPT-4).
### Interpretation
The bar chart suggests that newer language models like ChatGPT and GPT-4 are significantly safer than older models in terms of the percentage of answers considered safe. This could be due to improvements in training data, model architecture, or safety mechanisms implemented in the newer models. The older models davinci, OPT-1.3B, text-davinci-003, and flan-t5-xxl have a lower percentage of answers considered safe, indicating a potential need for improvement in their safety measures. The data demonstrates a clear trend of increasing safety with newer language models.