\n
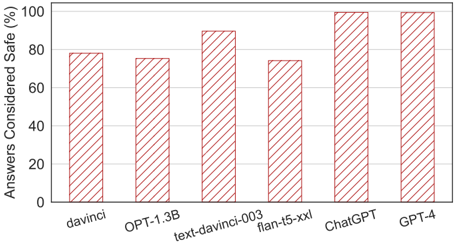
## Bar Chart: Safety Ratings of Large Language Models
### Overview
This is a bar chart comparing the percentage of answers considered "safe" from six different large language models (LLMs). The y-axis represents the percentage of safe answers, ranging from 0% to 100%. The x-axis lists the LLMs being evaluated: davinci, OPT-1.3B, text-davinci-003, flan-t5-xxl, ChatGPT, and GPT-4. Each LLM has a corresponding bar indicating its safety rating.
### Components/Axes
* **Y-axis Title:** "Answers Considered Safe (%)"
* **X-axis Labels:** davinci, OPT-1.3B, text-davinci-003, flan-t5-xxl, ChatGPT, GPT-4
* **Y-axis Scale:** 0, 20, 40, 60, 80, 100
* **Bar Color:** Red (consistent across all bars)
### Detailed Analysis
The bars represent the percentage of answers deemed safe for each model.
* **davinci:** The bar for davinci reaches approximately 80% on the y-axis.
* **OPT-1.3B:** The bar for OPT-1.3B reaches approximately 74% on the y-axis.
* **text-davinci-003:** The bar for text-davinci-003 reaches approximately 92% on the y-axis.
* **flan-t5-xxl:** The bar for flan-t5-xxl reaches approximately 78% on the y-axis.
* **ChatGPT:** The bar for ChatGPT reaches approximately 98% on the y-axis.
* **GPT-4:** The bar for GPT-4 reaches approximately 96% on the y-axis.
The bars generally increase in height from left to right, with some fluctuations.
### Key Observations
* ChatGPT exhibits the highest safety rating, nearly reaching 100%.
* GPT-4 also has a very high safety rating, slightly lower than ChatGPT.
* text-davinci-003 has a significantly higher safety rating than davinci, OPT-1.3B, and flan-t5-xxl.
* OPT-1.3B has the lowest safety rating among the models tested.
### Interpretation
The data suggests that the safety of responses generated by LLMs varies considerably depending on the model. Newer and more advanced models like ChatGPT and GPT-4 demonstrate substantially higher safety ratings compared to older models like davinci and OPT-1.3B. This improvement in safety could be attributed to advancements in model training, reinforcement learning from human feedback (RLHF), or the implementation of safety guardrails. The relatively high safety rating of text-davinci-003 indicates that even within the davinci family, newer iterations are safer. The chart highlights the importance of ongoing research and development to enhance the safety and reliability of LLMs, particularly as they become more widely deployed in real-world applications. The differences in safety ratings could be due to variations in the datasets used for training, the model architectures, and the specific safety mechanisms implemented.