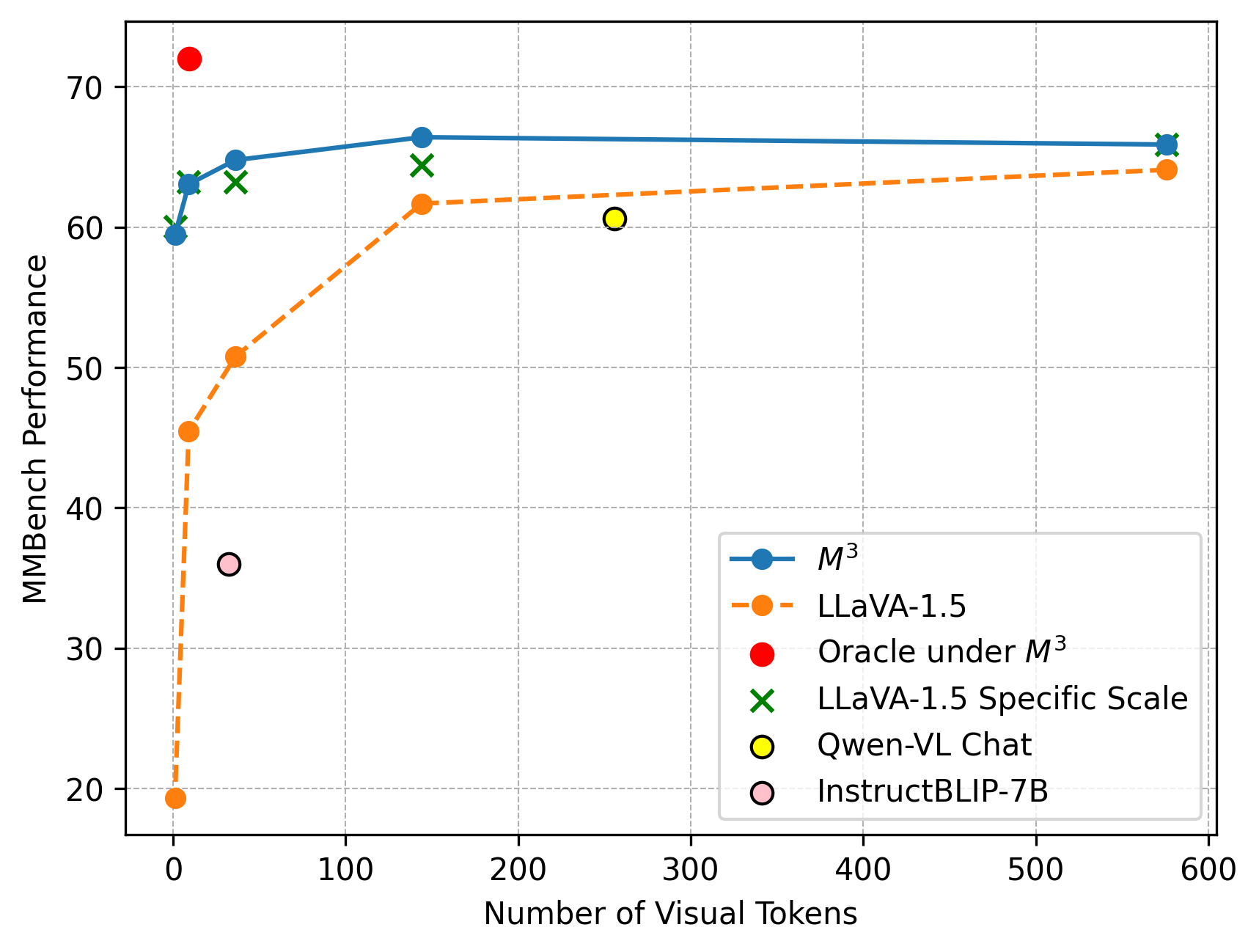
## Line Chart: MMBench Performance
### Overview
The line chart displays the performance of various models on the MMBench benchmark as a function of the number of visual tokens. The chart compares the performance of M3, LLaVA-1.5, Oracle under M3, LLaVA-1.5 Specific Scale, Qwen-VL Chat, and InstructBLIP-7B.
### Components/Axes
- **X-axis**: Number of Visual Tokens
- **Y-axis**: MMBench Performance
- **Legend**:
- Blue line: M3
- Orange line: LLaVA-1.5
- Red dot: Oracle under M3
- Green cross: LLaVA-1.5 Specific Scale
- Yellow circle: Qwen-VL Chat
- Pink circle: InstructBLIP-7B
### Detailed Analysis or ### Content Details
- **M3**: The performance of M3 remains relatively stable across the number of visual tokens, with a slight increase at the higher end.
- **LLaVA-1.5**: The performance of LLaVA-1.5 shows a significant increase as the number of visual tokens increases, peaking at around 500 tokens.
- **Oracle under M3**: The performance of Oracle under M3 is the lowest, with a slight increase at the higher end.
- **LLaVA-1.5 Specific Scale**: The performance of LLaVA-1.5 Specific Scale is similar to M3, with a slight increase at the higher end.
- **Qwen-VL Chat**: The performance of Qwen-VL Chat is the highest, with a slight increase at the higher end.
- **InstructBLIP-7B**: The performance of InstructBLIP-7B is the lowest, with a slight increase at the higher end.
### Key Observations
- **LLaVA-1.5** shows the highest performance across the number of visual tokens.
- **Oracle under M3** shows the lowest performance across the number of visual tokens.
- **Qwen-VL Chat** and **InstructBLIP-7B** show similar performance trends.
### Interpretation
The data suggests that LLaVA-1.5 is the most effective model for the MMBench benchmark, with the highest performance across the number of visual tokens. Oracle under M3 shows the lowest performance, suggesting that it may not be the best choice for this benchmark. Qwen-VL Chat and InstructBLIP-7B show similar performance trends, suggesting that they may be equally effective for this benchmark. The performance of LLaVA-1.5 Specific Scale is similar to M3, suggesting that it may be a good alternative to M3 for this benchmark.