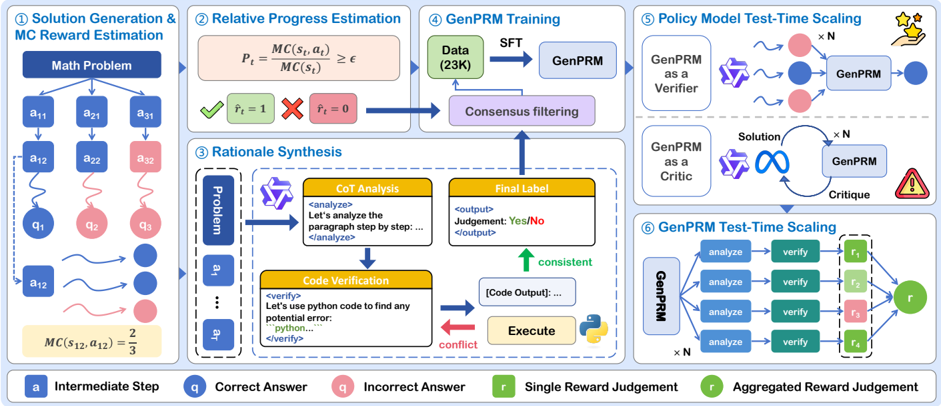
## Flowchart: Multi-Stage Problem-Solving Workflow with GenPRM Integration
### Overview
The diagram illustrates a six-stage technical workflow for solving mathematical problems using a combination of reinforcement learning (MC reward estimation), natural language reasoning, and large language model (GenPRM) verification. The process emphasizes iterative refinement through consensus filtering and test-time scaling.
### Components/Axes
1. **Stage 1: Solution Generation & MC Reward Estimation**
- **Math Problem** → Branches to **Intermediate Steps** (a₁₁, a₂₁, a₃₁)
- **Actions** (a₁₂, a₂₂, a₃₂) with **Correctness Labels** (q₁, q₂, q₃)
- **MC Reward Calculation**: MC(s₁₂,a₁₂) = 2/3
- **Color Coding**: Blue (correct), Pink (incorrect)
2. **Stage 2: Relative Progress Estimation**
- **Formula**: Pₜ = MC(sₜ,aₜ)/MC(sₜ) ≥ ε
- **Reward Flags**: Green check (rₜ=1), Red X (rₜ=0)
3. **Stage 3: GenPRM Training**
- **Data Input**: 23K samples
- **Process**: SFT → GenPRM → Consensus Filtering
- **Output**: Filtered training data
4. **Stage 4: Rational Synthesis**
- **CoT Analysis**: "Let's analyze the paragraph step by step..."
- **Code Verification**: Python code execution with error detection
- **Consistency Check**: Green arrow (consistent), Red arrow (conflict)
5. **Stage 5: Policy Model Test-Time Scaling**
- **GenPRM Roles**:
- **Verifier**: Multiple pink/blue nodes → Single verification
- **Critic**: Feedback loop with solution refinement
- **Output**: Final solution with star rating
6. **Stage 6: GenPRM Test-Time Scaling**
- **Parallel Analysis**: 4 "analyze" nodes → Aggregated reward (r)
- **Verification Nodes**: 4 "verify" nodes with mixed green/pink outputs
### Detailed Analysis
- **Math Problem Structure**:
- Initial problem branches to 3 action paths (a₁₁→a₁₂, a₂₁→a₂₂, a₃₁→a₃₂)
- Each path has correctness indicators (q₁=correct, q₂=incorrect, q₃=incorrect)
- Reward calculation shows 2/3 success rate for action a₁₂
- **GenPRM Integration**:
- Trained on 23K samples with supervised fine-tuning (SFT)
- Functions as both verifier (multiple parallel checks) and critic (feedback loop)
- Consensus filtering removes conflicting outputs
- **Test-Time Scaling**:
- 4 parallel analysis paths (×N) for complex problems
- Aggregated reward (r) combines multiple verification results
- Final output includes star rating system (⭐⭐⭐)
### Key Observations
1. **Iterative Refinement**:
- Solutions progress through multiple verification stages
- Conflicting code outputs trigger re-execution
2. **Reward Engineering**:
- MC rewards quantify solution quality
- Aggregated rewards (r) combine multiple verification results
3. **GenPRM Dual Role**:
- Acts as both verifier (parallel checks) and critic (feedback)
- Creates closed-loop improvement system
4. **Color-Coded Logic**:
- Blue = Correct actions/answers
- Pink = Incorrect actions/answers
- Green = Positive rewards/consistent outputs
- Red = Negative rewards/conflicts
### Interpretation
This workflow demonstrates a sophisticated approach to mathematical problem-solving that combines:
1. **Reinforcement Learning**: MC rewards guide solution quality
2. **Natural Language Reasoning**: CoT analysis breaks down complex problems
3. **LLM Verification**: GenPRM provides multi-perspective validation
4. **Test-Time Optimization**: Parallel analysis paths handle complexity
The system's strength lies in its ability to:
- Quantify solution quality through MC rewards
- Detect and resolve conflicts through consensus filtering
- Scale verification efforts through parallel analysis
- Improve solutions iteratively through critic feedback
Notable patterns include the emphasis on verification at multiple stages (initial actions, code execution, final solution) and the use of both positive (green) and negative (red) feedback signals to drive improvement. The star rating system suggests a final quality assessment beyond binary correctness.