## Diagram: Recurrent Neural Network (RNN) for Sentence Processing
### Overview
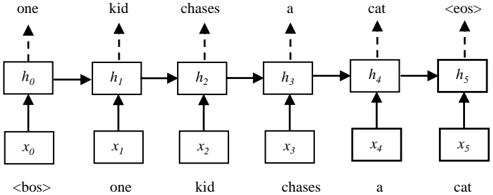
The image depicts a recurrent neural network (RNN) architecture processing a sentence. The diagram illustrates the flow of information through the network, showing the input sequence, hidden states, and output sequence. The sentence being processed is "one kid chases a cat".
### Components/Axes
* **Nodes:** The diagram consists of rectangular nodes representing hidden states (h0 to h5) and input/output tokens (x0 to x5).
* **Input Sequence:** The input sequence is represented by x0 to x5, corresponding to the tokens "<bos>", "one", "kid", "chases", "a", and "cat". "<bos>" represents the beginning of the sentence.
* **Hidden States:** The hidden states are represented by h0 to h5. Each hidden state receives input from the previous hidden state and the current input token.
* **Output Sequence:** The output sequence consists of the words "one", "kid", "chases", "a", "cat", and "<eos>". "<eos>" represents the end of the sentence.
* **Connections:** Solid arrows indicate the flow of information between hidden states. Dashed arrows indicate the relationship between hidden states and the output sequence. Vertical arrows connect the input tokens to the hidden states.
### Detailed Analysis
* **Input Layer:**
* x0: "<bos>" (beginning of sentence)
* x1: "one"
* x2: "kid"
* x3: "chases"
* x4: "a"
* x5: "cat"
* **Hidden Layer:**
* h0: Receives input from x0 and passes information to h1.
* h1: Receives input from x1 and h0, and passes information to h2.
* h2: Receives input from x2 and h1, and passes information to h3.
* h3: Receives input from x3 and h2, and passes information to h4.
* h4: Receives input from x4 and h3, and passes information to h5.
* h5: Receives input from x5 and h4.
* **Output Layer:**
* h0 outputs "one"
* h1 outputs "kid"
* h2 outputs "chases"
* h3 outputs "a"
* h4 outputs "cat"
* h5 outputs "<eos>" (end of sentence)
### Key Observations
* The diagram illustrates a sequence-to-sequence model where the input sequence is "one kid chases a cat" and the model predicts the same sequence, ending with an end-of-sentence token.
* Each hidden state (h_i) is connected to the corresponding input token (x_i) and the previous hidden state (h_{i-1}), demonstrating the recurrent nature of the network.
* The output at each time step is generated from the corresponding hidden state.
### Interpretation
The diagram represents a simplified RNN used for sequence processing, specifically for a task like language modeling or machine translation. The network processes the input sentence token by token, updating its hidden state at each step. The hidden state encapsulates information about the sequence seen so far, allowing the network to make predictions about the next token in the sequence. The use of "<bos>" and "<eos>" tokens indicates the start and end of the sentence, respectively, which are crucial for training and inference. The diagram demonstrates how the RNN maintains a memory of the past inputs through its hidden states, enabling it to handle sequential data effectively.