## Diagram: Reasoning Model Verification and Finetuning
### Overview
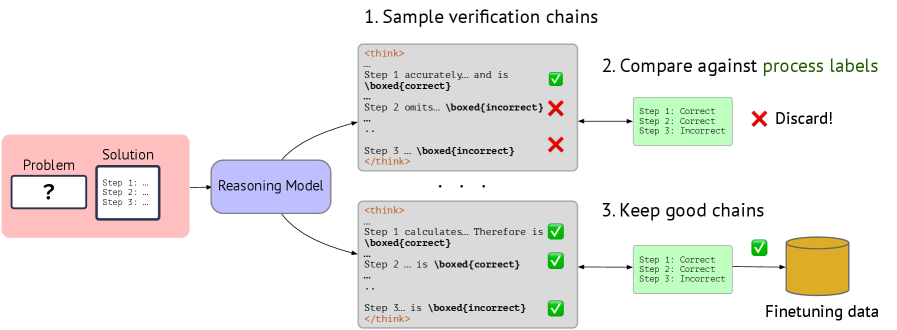
The image is a diagram illustrating a process for verifying reasoning chains generated by a reasoning model and using the verified chains for finetuning. The process involves sampling verification chains, comparing them against process labels, and keeping the good chains for finetuning data.
### Components/Axes
* **Problem/Solution Box (Left):** A pink rounded rectangle containing a "Problem" label and a question mark, next to a "Solution" label and three steps.
* **Reasoning Model (Center-Left):** A blue rounded rectangle labeled "Reasoning Model".
* **Sample Verification Chains (Top-Center):** Two gray rounded rectangles, each containing a "think" block with three steps, each step ending with either "\boxed{correct}" or "\boxed{incorrect}".
* **Compare Against Process Labels (Top-Right):** A green rounded rectangle containing labels "Step 1: Correct", "Step 2: Correct", and "Step 3: Incorrect", with a red "X Discard!" label.
* **Keep Good Chains (Bottom-Right):** A green rounded rectangle containing labels "Step 1: Correct", "Step 2: Correct", and "Step 3: Incorrect", with a green checkmark leading to a gold cylinder labeled "Finetuning data".
* **Connectors:** Arrows indicating the flow of information from the Problem/Solution box to the Reasoning Model, from the Reasoning Model to the Sample Verification Chains, from the Sample Verification Chains to the Compare Against Process Labels and Keep Good Chains, and from the Keep Good Chains to the Finetuning data.
### Detailed Analysis or ### Content Details
1. **Sample Verification Chains:**
* The first "think" block contains:
* "Step 1 accurately... and is \boxed{correct}" followed by a green checkmark.
* "Step 2 omits... \boxed{incorrect}" followed by a red X.
* "Step 3... \boxed{incorrect}" followed by a red X.
* The second "think" block contains:
* "Step 1 calculates... Therefore is \boxed{correct}" followed by a green checkmark.
* "Step 2... is \boxed{correct}" followed by a green checkmark.
* "Step 3... is \boxed{incorrect}" followed by a green checkmark.
2. **Compare Against Process Labels:**
* The green box contains:
* "Step 1: Correct"
* "Step 2: Correct"
* "Step 3: Incorrect"
* A red "X Discard!" indicates that this chain is discarded.
3. **Keep Good Chains:**
* The green box contains:
* "Step 1: Correct"
* "Step 2: Correct"
* "Step 3: Incorrect"
* A green checkmark indicates that this chain is kept.
### Key Observations
* The diagram illustrates a pipeline for generating, verifying, and filtering reasoning chains.
* The verification process involves comparing the model's output against process labels to determine the correctness of each step.
* Chains with errors are discarded, while good chains are used for finetuning the model.
### Interpretation
The diagram describes a method for improving the quality of reasoning models by using a verification process to filter out incorrect reasoning chains and using the correct chains to finetune the model. This process aims to enhance the model's accuracy and reliability by training it on high-quality data. The use of "think" blocks suggests that the reasoning model is generating step-by-step explanations, which are then evaluated for correctness. The diagram highlights the importance of data quality in training machine learning models and provides a framework for ensuring that the training data is accurate and reliable.