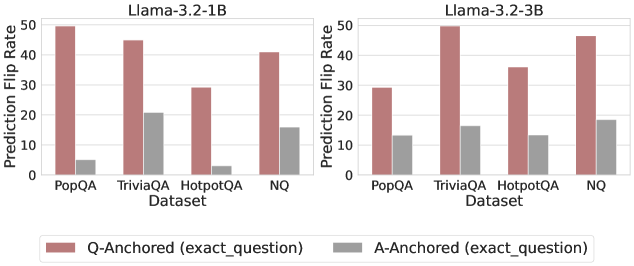
## Bar Chart: Prediction Flip Rate Comparison for Llama-3.2 Models
### Overview
The image presents a comparative bar chart analyzing prediction flip rates for two versions of the Llama-3.2 language model (1B and 3B parameter sizes) across four question-answering datasets: PopQA, TriviaQA, HotpotQA, and NQ. Two anchoring methods are compared: Q-Anchored (exact_question) and A-Anchored (exact_question), represented by red and gray bars respectively.
### Components/Axes
- **X-Axis (Datasets)**:
- PopQA (leftmost)
- TriviaQA
- HotpotQA
- NQ (rightmost)
- **Y-Axis (Prediction Flip Rate)**:
- Scale: 0 to 50 (increments of 10)
- **Legend**:
- Red: Q-Anchored (exact_question)
- Gray: A-Anchored (exact_question)
- **Model Versions**:
- Left section: Llama-3.2-1B
- Right section: Llama-3.2-3B
### Detailed Analysis
#### Llama-3.2-1B (Left Section)
- **PopQA**:
- Q-Anchored: ~50
- A-Anchored: ~5
- **TriviaQA**:
- Q-Anchored: ~45
- A-Anchored: ~20
- **HotpotQA**:
- Q-Anchored: ~30
- A-Anchored: ~3
- **NQ**:
- Q-Anchored: ~40
- A-Anchored: ~15
#### Llama-3.2-3B (Right Section)
- **PopQA**:
- Q-Anchored: ~30
- A-Anchored: ~13
- **TriviaQA**:
- Q-Anchored: ~50
- A-Anchored: ~17
- **HotpotQA**:
- Q-Anchored: ~35
- A-Anchored: ~13
- **NQ**:
- Q-Anchored: ~47
- A-Anchored: ~19
### Key Observations
1. **Q-Anchored Dominance**:
- Q-Anchored consistently outperforms A-Anchored across all datasets and model sizes, with flip rates 3-10x higher.
2. **Model Size Impact**:
- Llama-3.2-3B shows reduced Q-Anchored performance in PopQA (-40%) and HotpotQA (-13%) compared to 1B, but matches or exceeds in TriviaQA (+11%) and NQ (+18%).
3. **A-Anchored Variability**:
- A-Anchored rates remain relatively stable between model sizes, with minor increases in TriviaQA (+35%) and NQ (+27%).
4. **Dataset-Specific Trends**:
- NQ dataset shows the largest gap between anchoring methods (~30 points for 1B, ~28 points for 3B).
### Interpretation
The data suggests that Q-Anchored (exact_question) significantly improves prediction stability compared to A-Anchored (exact_question), with performance gains scaling with model complexity in most cases. However, the Llama-3.2-3B model exhibits unexpected underperformance in Q-Anchored for PopQA and HotpotQA, potentially indicating dataset-specific architectural limitations. The NQ dataset's high flip rates for both methods suggest it may represent particularly challenging or ambiguous question types. The consistent A-Anchored performance across model sizes implies that answer anchoring provides more stable baseline behavior regardless of model capacity.