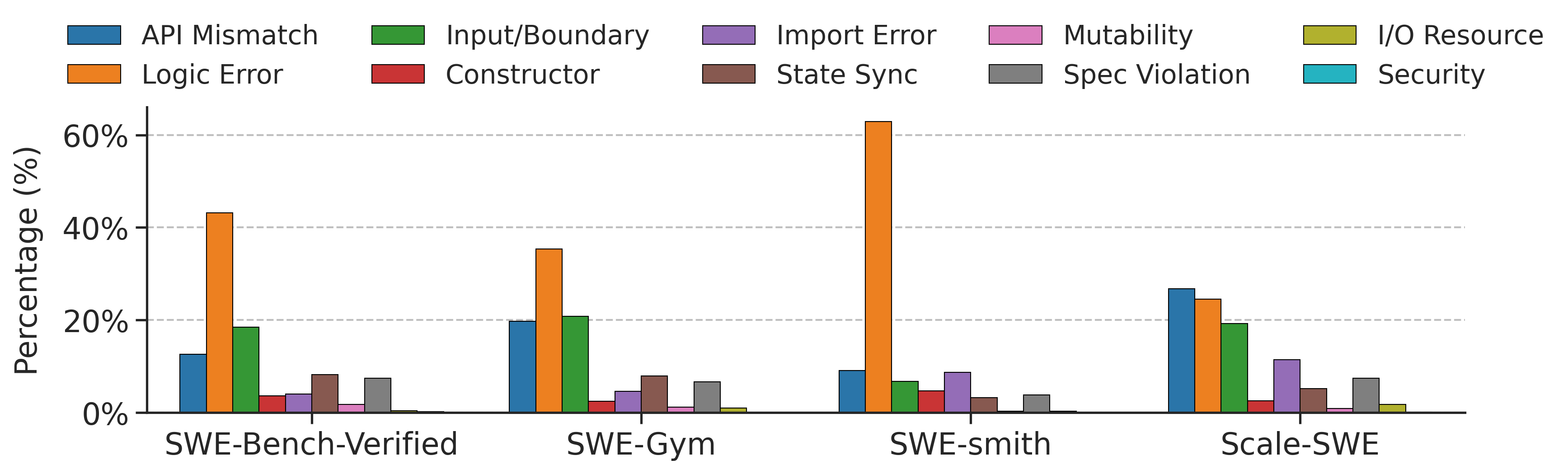
## Grouped Bar Chart: Error Type Distribution Across Software Engineering Benchmarks
### Overview
The image displays a grouped bar chart comparing the percentage distribution of ten different software error types across four distinct software engineering (SWE) benchmark datasets. The chart is designed to show the relative prevalence of each error category within each benchmark.
### Components/Axes
* **Chart Type:** Grouped Bar Chart.
* **Y-Axis:** Labeled "Percentage (%)". The scale runs from 0% to 60% with major gridlines at 20% intervals (0%, 20%, 40%, 60%).
* **X-Axis:** Represents four distinct benchmark datasets. The categories are, from left to right:
1. `SWE-Bench-Verified`
2. `SWE-Gym`
3. `SWE-smith`
4. `Scale-SWE`
* **Legend:** Positioned at the top of the chart, spanning its full width. It defines ten error types with associated colors:
* **Blue:** API Mismatch
* **Orange:** Logic Error
* **Green:** Input/Boundary
* **Red:** Constructor
* **Purple:** Import Error
* **Brown:** State Sync
* **Pink:** Mutability
* **Grey:** Spec Violation
* **Olive Green:** I/O Resource
* **Teal:** Security
### Detailed Analysis
Below are the approximate percentage values for each error type within each benchmark dataset. Values are estimated based on bar height relative to the y-axis gridlines.
**1. SWE-Bench-Verified**
* **Logic Error (Orange):** ~43% (Highest in this group)
* **Input/Boundary (Green):** ~19%
* **API Mismatch (Blue):** ~13%
* **State Sync (Brown):** ~8%
* **Spec Violation (Grey):** ~7%
* **Import Error (Purple):** ~4%
* **Constructor (Red):** ~3%
* **Mutability (Pink):** ~2%
* **I/O Resource (Olive):** ~1%
* **Security (Teal):** ~0% (Not visible)
**2. SWE-Gym**
* **Logic Error (Orange):** ~36% (Highest in this group)
* **Input/Boundary (Green):** ~21%
* **API Mismatch (Blue):** ~20%
* **State Sync (Brown):** ~8%
* **Spec Violation (Grey):** ~7%
* **Import Error (Purple):** ~4%
* **Constructor (Red):** ~2%
* **Mutability (Pink):** ~1%
* **I/O Resource (Olive):** ~1%
* **Security (Teal):** ~0% (Not visible)
**3. SWE-smith**
* **Logic Error (Orange):** ~63% (Highest bar in the entire chart)
* **API Mismatch (Blue):** ~9%
* **Import Error (Purple):** ~9%
* **Input/Boundary (Green):** ~7%
* **Constructor (Red):** ~4%
* **State Sync (Brown):** ~3%
* **Spec Violation (Grey):** ~3%
* **Mutability (Pink):** ~1%
* **I/O Resource (Olive):** ~0% (Not visible)
* **Security (Teal):** ~0% (Not visible)
**4. Scale-SWE**
* **API Mismatch (Blue):** ~27% (Highest in this group)
* **Logic Error (Orange):** ~25%
* **Input/Boundary (Green):** ~20%
* **Import Error (Purple):** ~12%
* **Spec Violation (Grey):** ~7%
* **State Sync (Brown):** ~5%
* **Constructor (Red):** ~2%
* **Mutability (Pink):** ~1%
* **I/O Resource (Olive):** ~1%
* **Security (Teal):** ~0% (Not visible)
### Key Observations
1. **Dominance of Logic Errors:** Logic Error is the most prevalent error type in three of the four benchmarks (SWE-Bench-Verified, SWE-Gym, SWE-smith), peaking at over 60% in SWE-smith.
2. **Shift in Scale-SWE:** The `Scale-SWE` dataset shows a different pattern, where `API Mismatch` becomes the most common error type (~27%), surpassing Logic Error (~25%).
3. **Consistent Secondary Errors:** `Input/Boundary` and `API Mismatch` are consistently significant across all datasets, typically ranging between 7% and 27%.
4. **Low-Frequency Errors:** `Security`, `I/O Resource`, `Mutability`, and `Constructor` errors are consistently low across all benchmarks, each generally below 5%.
5. **Variability in Import Errors:** The prevalence of `Import Error` varies notably, from ~4% in the first two benchmarks to ~9% in SWE-smith and ~12% in Scale-SWE.
### Interpretation
This chart provides a comparative analysis of the types of bugs or errors found in different software engineering evaluation benchmarks. The data suggests that:
* **Benchmark Character:** The benchmarks are not homogeneous. `SWE-smith` appears heavily skewed towards logic-based failures, while `Scale-SWE` presents a more balanced challenge with a higher proportion of API integration issues. This implies that performance on these benchmarks may test different aspects of a software engineering agent's capabilities.
* **Common Failure Modes:** Across these diverse benchmarks, issues related to core program logic (`Logic Error`), interaction with external code (`API Mismatch`), and handling of inputs (`Input/Boundary`) constitute the vast majority of observed errors. This highlights these areas as critical focus points for improving automated code generation or repair systems.
* **Anomaly - SWE-smith:** The extremely high concentration of Logic Errors in `SWE-smith` (over 60%) is a notable outlier. This could indicate that this specific benchmark is designed to test or inadvertently captures scenarios where logical reasoning is the primary point of failure.
* **Implication for Tool Development:** Developers of AI programming assistants or testing tools should note that while logic errors are common, the significant presence of API and input-related errors, especially in `Scale-SWE`, indicates that tools must also be robust in handling integration and interface specifications. The near-absence of Security and I/O Resource errors in this visualization may reflect the nature of the benchmark tasks or a potential gap in their coverage.