## Line Chart: Performance (Mstencil/s) vs. Input Length
### Overview
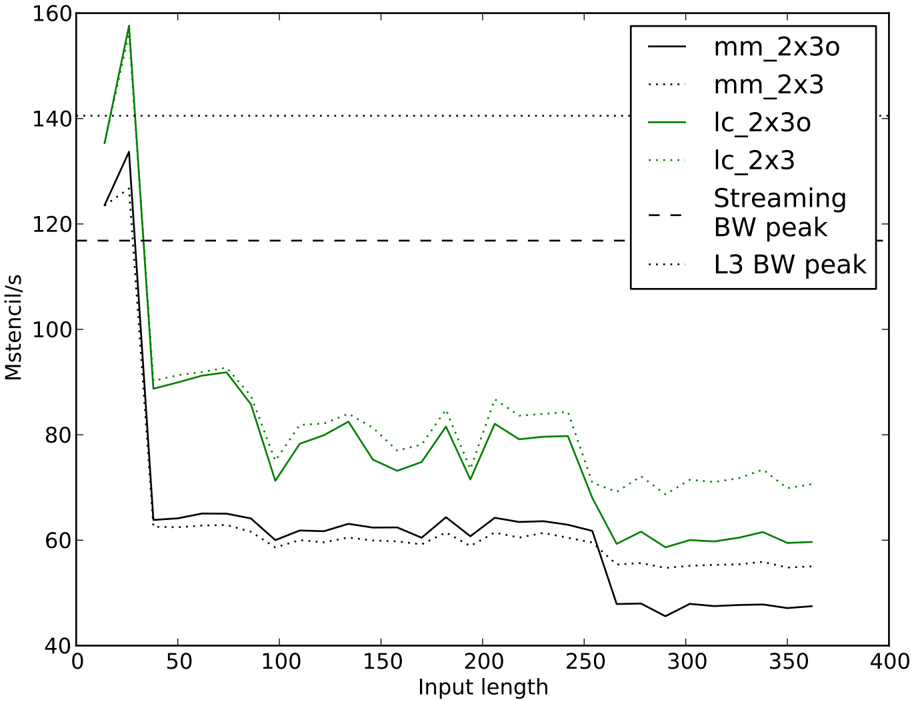
This chart illustrates the performance, measured in "Mstencil/s" (Mega-stencils per second), of four distinct computational configurations across varying "Input length" values. The chart includes two horizontal reference lines indicating theoretical bandwidth peaks. The data suggests a performance profile typical of memory-bound applications where performance degrades as the working set size exceeds cache capacities.
### Components/Axes
* **Y-Axis:** Labeled "Mstencil/s". The scale ranges from 40 to 160, with increments of 20.
* **X-Axis:** Labeled "Input length". The scale ranges from 0 to 400, with increments of 50.
* **Legend:** Located in the top-right quadrant.
* `mm_2x3o`: Solid black line.
* `mm_2x3`: Dotted black line.
* `lc_2x3o`: Solid green line.
* `lc_2x3`: Dotted green line.
* `Streaming BW peak`: Dashed horizontal line (black).
* `L3 BW peak`: Dotted horizontal line (black).
### Detailed Analysis
The chart displays four data series and two horizontal reference lines.
**Reference Lines:**
* **L3 BW peak (Dotted horizontal line):** Positioned at approximately 141 Mstencil/s.
* **Streaming BW peak (Dashed horizontal line):** Positioned at approximately 117 Mstencil/s.
**Data Series Trends:**
All four data series follow a similar general shape: an initial sharp spike, a steep decline, a period of moderate fluctuation, and a final drop-off.
1. **Initial Phase (Input length 0–40):**
* **Trend:** All lines slope sharply upward to a peak at input length ~25, followed by a precipitous drop.
* **Values at Peak (~25):**
* `lc_2x3o` (Solid green): ~158 Mstencil/s.
* `mm_2x3o` (Solid black): ~134 Mstencil/s.
* `lc_2x3` (Dotted green): ~128 Mstencil/s.
* `mm_2x3` (Dotted black): ~124 Mstencil/s.
2. **Mid-Range Phase (Input length 40–250):**
* **Trend:** After the initial drop, performance stabilizes into a fluctuating plateau.
* **Green Series (`lc_2x3o`, `lc_2x3`):** These lines remain consistently higher than the black series, fluctuating between ~70 and ~90 Mstencil/s.
* **Black Series (`mm_2x3o`, `mm_2x3`):** These lines remain lower, fluctuating between ~60 and ~65 Mstencil/s.
3. **Late-Range Phase (Input length 250–360):**
* **Trend:** A second, significant drop occurs at input length ~250 for all series.
* **Values post-drop:**
* Green series (`lc_2x3o`, `lc_2x3`) settle between ~60 and ~70 Mstencil/s.
* Black series (`mm_2x3o`, `mm_2x3`) settle between ~48 and ~55 Mstencil/s.
### Key Observations
* **Performance Hierarchy:** The `lc` configurations (green) consistently outperform the `mm` configurations (black) across all input lengths.
* **Cache Cliffs:** There are two distinct "cliffs" in performance. The first at input length ~25, where performance drops from the peak (exceeding L3 BW) to a lower tier. The second at input length ~250, where performance drops again, likely indicating the working set has exceeded the L3 cache capacity and is now constrained by main memory bandwidth.
* **Configuration Impact:** The "o" suffix (solid lines) generally provides a slight performance advantage or parity compared to the non-"o" versions (dotted lines) within the same color group.
### Interpretation
This chart is a classic representation of memory hierarchy performance profiling.
* **The "Spike":** The initial peak at input length ~25 suggests that for very small input sizes, the data fits entirely within the fastest cache (likely L1 or L2), allowing for extremely high throughput that approaches or exceeds the L3 bandwidth peak.
* **The "Plateau":** As the input length increases beyond ~25, the data no longer fits in the fastest cache, forcing the processor to fetch from slower memory levels (likely L3), resulting in the drop to the 60–90 Mstencil/s range.
* **The "Cliff":** The drop at input length ~250 indicates that the working set size has exceeded the L3 cache capacity. The system is now forced to stream data from main memory (RAM), which is significantly slower, causing the final performance degradation to the 48–70 Mstencil/s range.
* **Optimization:** The `lc` configurations are clearly more cache-efficient than the `mm` configurations, as they maintain higher throughput even after the working set exceeds the cache limits. This suggests that `lc` likely employs better data tiling, prefetching, or memory access patterns that reduce the penalty of main memory latency.