TECHNICAL ASSET FINGERPRINT
e70a16f5f046c1d307351c80
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
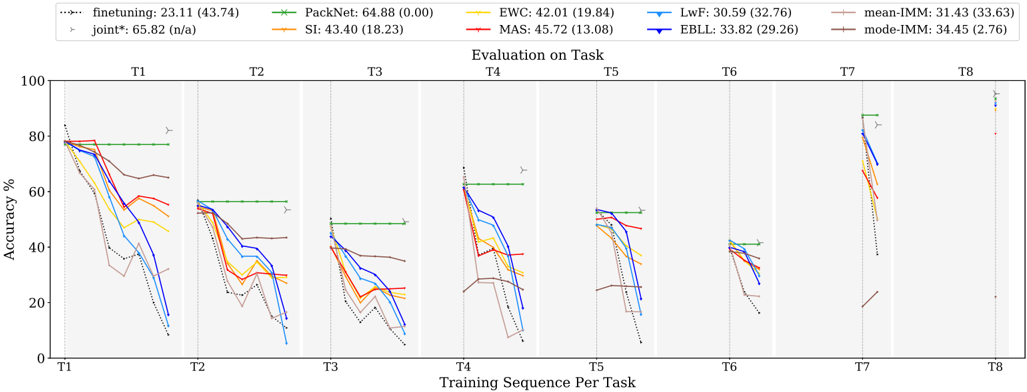
## Line Chart: Evaluation on Task
### Overview
The image is a line chart comparing the performance of different continual learning algorithms across a sequence of tasks (T1 to T8). The y-axis represents accuracy percentage, and the x-axis represents the training sequence per task. Each line represents a different algorithm, and the chart shows how the accuracy of each algorithm changes as it is trained on successive tasks.
### Components/Axes
* **X-axis:** Training Sequence Per Task (T1, T2, T3, T4, T5, T6, T7, T8)
* **Y-axis:** Accuracy % (Scale from 0 to 100)
* **Title:** Evaluation on Task
* **Legend (Top-Left):**
* finetuning (dotted black line): 23.11 (43.74)
* joint\* (gray line with triangle markers): 65.82 (n/a)
* PackNet (green line): 64.88 (0.00)
* SI (orange line): 43.40 (18.23)
* EWC (yellow line): 42.01 (19.84)
* MAS (red line): 45.72 (13.08)
* LwF (light blue line): 30.59 (32.76)
* EBLL (dark blue line): 33.82 (29.26)
* mean-IMM (brown line): 31.43 (33.63)
* mode-IMM (purple line): 34.45 (2.76)
### Detailed Analysis
The chart is divided into eight sections, one for each task (T1 to T8). Each section shows the accuracy of the different algorithms after training on that task.
* **finetuning (dotted black line):** Starts high and consistently decreases across all tasks.
* **joint\* (gray line with triangle markers):** Remains relatively stable and high across all tasks.
* **PackNet (green line):** Remains constant across all tasks.
* **SI (orange line):** Starts high and decreases across tasks.
* **EWC (yellow line):** Starts high and decreases across tasks.
* **MAS (red line):** Starts high and decreases across tasks.
* **LwF (light blue line):** Starts high and decreases across tasks.
* **EBLL (dark blue line):** Starts high and decreases across tasks.
* **mean-IMM (brown line):** Starts high and decreases across tasks.
* **mode-IMM (purple line):** Starts high and decreases across tasks.
**Task 1 (T1):**
* finetuning: Starts at approximately 78% and decreases.
* joint\*: Starts at approximately 82%.
* PackNet: Starts at approximately 78%.
* SI: Starts at approximately 76%.
* EWC: Starts at approximately 74%.
* MAS: Starts at approximately 78%.
* LwF: Starts at approximately 76%.
* EBLL: Starts at approximately 78%.
* mean-IMM: Starts at approximately 78%.
* mode-IMM: Starts at approximately 78%.
**Task 2 (T2):**
* finetuning: Decreases to approximately 38%.
* joint\*: Remains at approximately 82%.
* PackNet: Remains at approximately 57%.
* SI: Decreases to approximately 58%.
* EWC: Decreases to approximately 54%.
* MAS: Decreases to approximately 56%.
* LwF: Decreases to approximately 56%.
* EBLL: Decreases to approximately 58%.
* mean-IMM: Decreases to approximately 66%.
* mode-IMM: Decreases to approximately 64%.
**Task 3 (T3):**
* finetuning: Decreases to approximately 24%.
* joint\*: Remains at approximately 82%.
* PackNet: Remains at approximately 50%.
* SI: Decreases to approximately 40%.
* EWC: Decreases to approximately 36%.
* MAS: Decreases to approximately 38%.
* LwF: Decreases to approximately 36%.
* EBLL: Decreases to approximately 38%.
* mean-IMM: Decreases to approximately 40%.
* mode-IMM: Decreases to approximately 40%.
**Task 4 (T4):**
* finetuning: Decreases to approximately 10%.
* joint\*: Remains at approximately 82%.
* PackNet: Remains at approximately 64%.
* SI: Decreases to approximately 20%.
* EWC: Decreases to approximately 20%.
* MAS: Decreases to approximately 20%.
* LwF: Decreases to approximately 20%.
* EBLL: Decreases to approximately 20%.
* mean-IMM: Decreases to approximately 30%.
* mode-IMM: Decreases to approximately 30%.
**Task 5 (T5):**
* finetuning: Increases to approximately 10%.
* joint\*: Remains at approximately 82%.
* PackNet: Remains at approximately 52%.
* SI: Increases to approximately 48%.
* EWC: Increases to approximately 50%.
* MAS: Increases to approximately 52%.
* LwF: Increases to approximately 52%.
* EBLL: Increases to approximately 52%.
* mean-IMM: Increases to approximately 48%.
* mode-IMM: Increases to approximately 48%.
**Task 6 (T6):**
* finetuning: Decreases to approximately 20%.
* joint\*: Remains at approximately 82%.
* PackNet: Remains at approximately 50%.
* SI: Decreases to approximately 38%.
* EWC: Decreases to approximately 38%.
* MAS: Decreases to approximately 38%.
* LwF: Decreases to approximately 38%.
* EBLL: Decreases to approximately 38%.
* mean-IMM: Decreases to approximately 38%.
* mode-IMM: Decreases to approximately 38%.
**Task 7 (T7):**
* finetuning: Decreases to approximately 10%.
* joint\*: Remains at approximately 82%.
* PackNet: Remains at approximately 90%.
* SI: Decreases to approximately 68%.
* EWC: Decreases to approximately 66%.
* MAS: Decreases to approximately 64%.
* LwF: Decreases to approximately 72%.
* EBLL: Decreases to approximately 74%.
* mean-IMM: Decreases to approximately 68%.
* mode-IMM: Decreases to approximately 68%.
**Task 8 (T8):**
* finetuning: Decreases to approximately 10%.
* joint\*: Remains at approximately 96%.
* PackNet: Remains at approximately 96%.
* SI: Remains at approximately 96%.
* EWC: Remains at approximately 96%.
* MAS: Remains at approximately 96%.
* LwF: Remains at approximately 96%.
* EBLL: Remains at approximately 96%.
* mean-IMM: Remains at approximately 96%.
* mode-IMM: Remains at approximately 96%.
### Key Observations
* The "joint\*" algorithm consistently maintains high accuracy across all tasks.
* The "PackNet" algorithm maintains a relatively stable accuracy across all tasks.
* The "finetuning" algorithm experiences a significant drop in accuracy as the training sequence progresses, indicating catastrophic forgetting.
* Other algorithms (SI, EWC, MAS, LwF, EBLL, mean-IMM, mode-IMM) show a decline in accuracy as the training sequence progresses, but not as severe as "finetuning".
### Interpretation
The chart demonstrates the challenge of continual learning, where models tend to forget previously learned tasks when trained on new ones. The "joint\*" algorithm serves as an upper bound, showing the performance that can be achieved when all tasks are learned jointly. The "finetuning" algorithm highlights the problem of catastrophic forgetting. The other algorithms represent different approaches to mitigate catastrophic forgetting, with varying degrees of success. The performance drop observed in most algorithms suggests that continual learning remains a challenging problem, and further research is needed to develop more robust algorithms.
DECODING INTELLIGENCE...