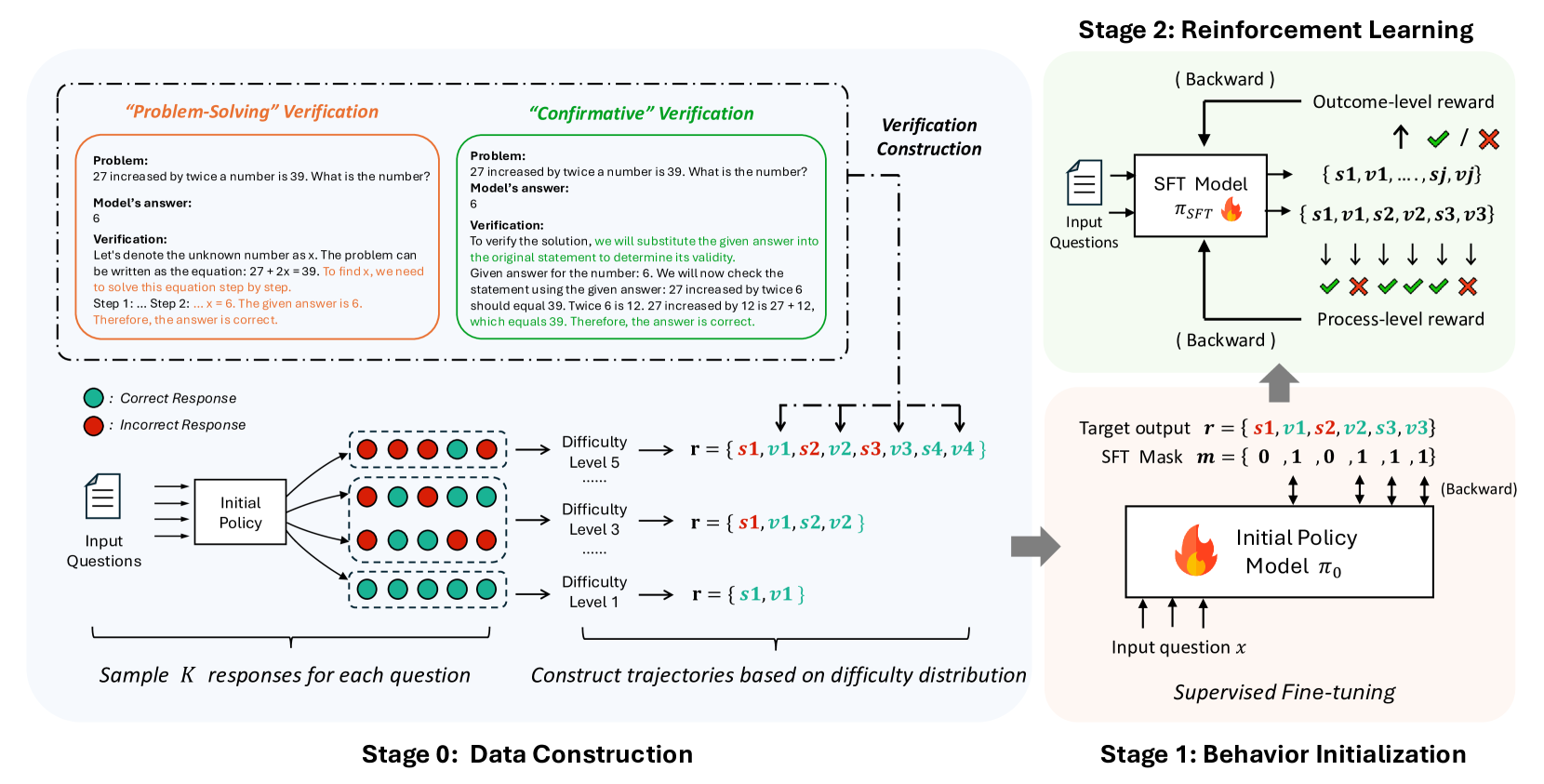
## Data Construction and Reinforcement Learning Diagram
### Overview
The image illustrates a multi-stage process involving data construction, behavior initialization, and reinforcement learning. It details how a model learns to solve problems through verification and trajectory construction based on difficulty levels.
### Components/Axes
* **Stages:** The diagram is divided into three stages:
* Stage 0: Data Construction
* Stage 1: Behavior Initialization
* Stage 2: Reinforcement Learning
* **Verification Methods:** Two verification methods are presented:
* "Problem-Solving" Verification (left side, outlined in orange)
* "Confirmative" Verification (right side, outlined in green)
* **Legend:** Located in the bottom-left corner:
* Green circle: Correct Response
* Red circle: Incorrect Response
* **Difficulty Levels:** Three difficulty levels are shown:
* Difficulty Level 1
* Difficulty Level 3
* Difficulty Level 5
* **Models:**
* Initial Policy Model π₀
* SFT Model π_SFT
### Detailed Analysis or ### Content Details
**Stage 0: Data Construction**
* **Input Questions:** Input questions are fed into an "Initial Policy" block.
* **Sample Responses:** The "Initial Policy" block outputs a set of responses, represented by green (correct) and red (incorrect) circles.
* The first row of responses contains 3 red and 3 green circles.
* The second row of responses contains 4 green and 2 red circles.
* The third row of responses contains 5 green and 1 red circles.
* **Sample K responses for each question:** Text below the responses.
* **Difficulty Levels:** Trajectories are constructed based on difficulty distribution.
* Difficulty Level 1: r = {s1, v1}
* Difficulty Level 3: r = {s1, v1, s2, v2}
* Difficulty Level 5: r = {s1, v1, s2, v2, s3, v3, s4, v4}
* The variables s1, s2, s3, s4 are black.
* The variables v1, v2, v3, v4 are teal.
* The incorrect responses are red.
**Stage 1: Behavior Initialization**
* **Initial Policy Model:** An "Initial Policy Model π₀" block receives "Input question x".
* **Supervised Fine-tuning:** The model undergoes supervised fine-tuning.
* **Target Output:** The target output is defined as r = {s1, v1, s2, v2, s3, v3}.
* The variables s1, s2, s3 are black.
* The variables v1, v2, v3 are teal.
* The incorrect responses are red.
* **SFT Mask:** An SFT Mask m = {0, 1, 0, 1, 1, 1} is applied.
**Stage 2: Reinforcement Learning**
* **SFT Model:** An "SFT Model π_SFT" block receives "Input Questions".
* **Outcome-level reward:** The model receives outcome-level rewards (checkmark for correct, X for incorrect).
* **Process-level reward:** The model receives process-level rewards (checkmarks and X's).
* The sequence of rewards is: checkmark, X, checkmark, checkmark, checkmark, X.
* **Outputs:** The SFT Model outputs two sets of data:
* {s1, v1, ..., sj, vj}
* {s1, v1, s2, v2, s3, v3}
**Verification Sections**
* **"Problem-Solving" Verification:**
* Problem: "27 increased by twice a number is 39. What is the number?"
* Model's answer: 6
* Verification: "Let's denote the unknown number as x. The problem can be written as the equation: 27 + 2x = 39. To find x, we need to solve this equation step by step. Step 1:... Step 2: ... x = 6. The given answer is 6. Therefore, the answer is correct."
* **"Confirmative" Verification:**
* Problem: "27 increased by twice a number is 39. What is the number?"
* Model's answer: 6
* Verification: "To verify the solution, we will substitute the given answer into the original statement to determine its validity. Given answer for the number: 6. We will now check the statement using the given answer: 27 increased by twice 6 should equal 39. Twice 6 is 12. 27 increased by 12 is 27 + 12, which equals 39. Therefore, the answer is correct."
### Key Observations
* The diagram illustrates a learning process that starts with initial data construction, moves to behavior initialization, and culminates in reinforcement learning.
* The difficulty levels increase the complexity of the trajectories.
* The verification methods provide different approaches to validating the model's answers.
### Interpretation
The diagram presents a structured approach to training a model to solve problems. It highlights the importance of data construction, initial behavior setup, and reinforcement learning. The use of different verification methods and difficulty levels suggests a comprehensive training strategy. The SFT Mask in Stage 1 likely serves to focus the model's learning on specific aspects of the target output. The overall process aims to improve the model's accuracy and problem-solving abilities through iterative learning and feedback.