\n
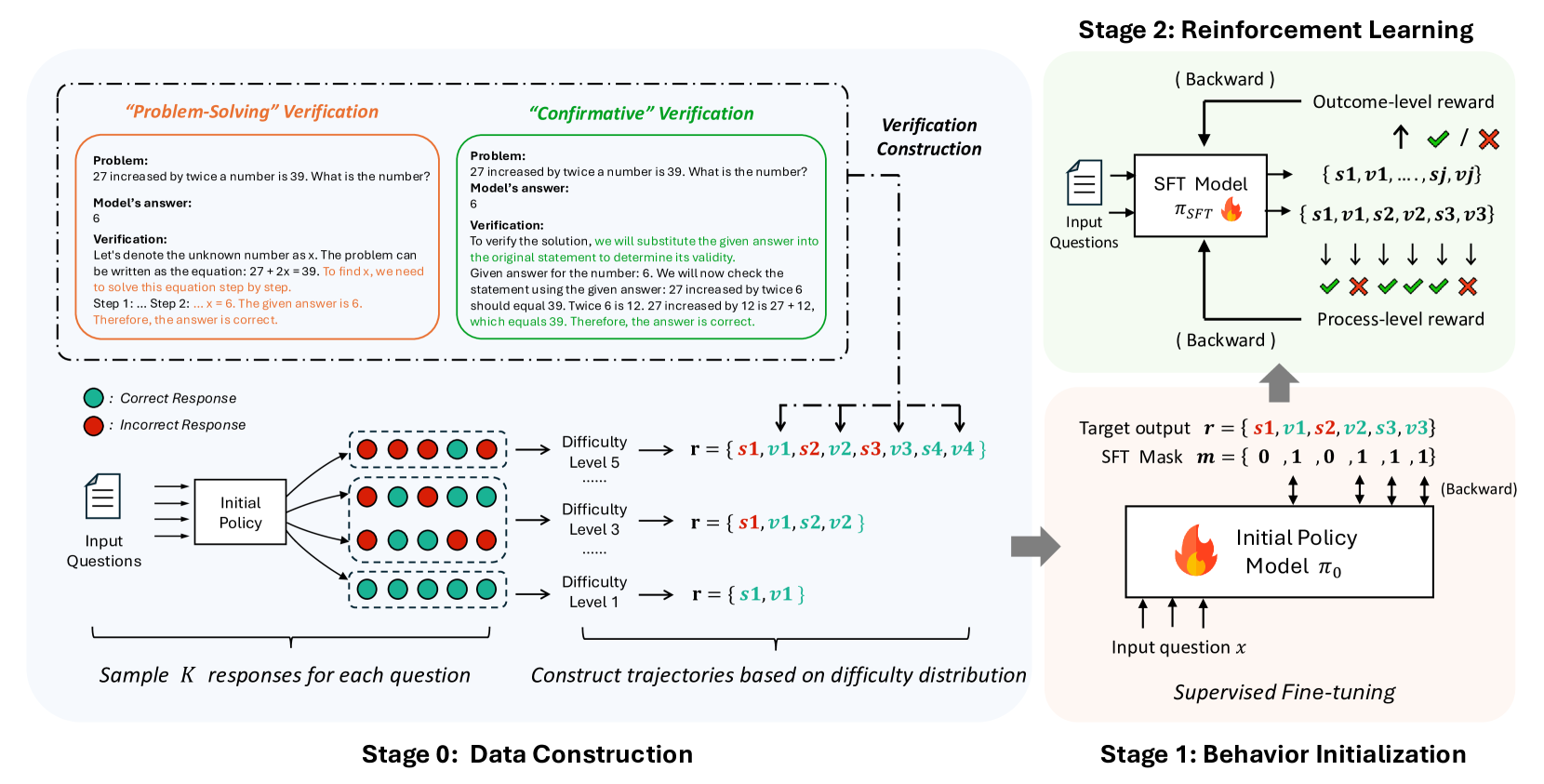
## Diagram: Reinforcement Learning for Verification
### Overview
This diagram illustrates a multi-stage process for training a model to verify mathematical problem solutions using reinforcement learning. The process is broken down into four stages: Data Construction, Reinforcement Learning, Behavior Initialization, and Verification Construction. It details the flow of information, the types of rewards used, and the components involved in each stage.
### Components/Axes
The diagram is structured into four main stages, labeled "Stage 0: Data Construction", "Stage 1: Behavior Initialization", "Stage 2: Reinforcement Learning", and "Verification Construction". Each stage contains several components and arrows indicating the flow of data.
* **Stage 0: Data Construction:** Includes "Input Questions", "Initial Policy", "Difficulty Level 1", "Difficulty Level 3", "Difficulty Level 5", and "Sample k responses for each question". Green circles represent "Correct Response" and red circles represent "Incorrect Response".
* **Stage 1: Behavior Initialization:** Includes "Input question x", "Initial Policy", "Model π₀", and "Supervised Fine-tuning".
* **Stage 2: Reinforcement Learning:** Includes "SFT Model", "Input Questions", "Outcome-level reward", "Process-level reward", and the set of states {s1, v1, s2, v2, s3, v3}.
* **Verification Construction:** Contains two problem examples: "Problem-Solving" Verification and "Confirmatory" Verification.
### Detailed Analysis or Content Details
**Stage 0: Data Construction**
* Input Questions are fed into an Initial Policy.
* The Initial Policy generates responses, which are categorized as either Correct (green circle) or Incorrect (red circle).
* Responses are constructed into trajectories based on difficulty distribution, with three difficulty levels: Level 1, Level 3, and Level 5.
* Difficulty Level 1: r = {s1, v1}
* Difficulty Level 3: r = {s1, v1, s2, v2}
* Difficulty Level 5: r = {s1, v1, s2, v2, s3, v3, s4, v4}
* The output is "Sample k responses for each question".
**Stage 1: Behavior Initialization**
* An Input question x is fed into the Initial Policy.
* The Initial Policy generates a Model π₀.
* The Model π₀ undergoes Supervised Fine-tuning.
**Stage 2: Reinforcement Learning**
* Input Questions are fed into an SFT Model.
* The SFT Model generates a sequence of states {s1, v1, s2, v2, s3, v3}.
* Two types of rewards are used: Outcome-level reward (represented by a checkmark or cross) and Process-level reward.
* The flow is "Backward".
**Verification Construction**
* **"Problem-Solving" Verification:**
* Problem: "27 increased by twice a number is 39. What is the number?"
* Model's answer: 6
* Verification: "Let's denote the unknown number as x. The problem can be written as the equation: 27 + 2x = 39. To find x, we need to solve this equation step by step. Step 1: ... Step 6. The given answer is 6. Therefore, the answer is correct."
* **"Confirmatory" Verification:**
* Problem: "27 increased by twice a number is 39. What is the number?"
* Model's answer: 6
* Verification: "To verify the solution, we will substitute the given answer into the original statement to determine its validity. Given answer for the number 6. We will now check the statement using the given answer: 27 increased by twice 6 should equal 39. Twice 6 is 12. 27 increased by 12 is 27 + 12, which equals 39. Therefore, the answer is correct."
**Target Output**
* Target output r = {s1, v1, s2, v2, s3, v3}
* SFT Mask m = {0, 1, 0, 1, 1, 1, 1}
### Key Observations
* The diagram emphasizes a backward flow of information in the Reinforcement Learning stage, indicated by the "Backward" labels.
* The verification process provides both a problem-solving approach and a confirmatory approach.
* The SFT Mask suggests a selective application of the SFT model to certain states.
* The use of both Outcome-level and Process-level rewards indicates a nuanced reward structure.
### Interpretation
The diagram outlines a sophisticated approach to training a verification model. The data construction stage generates a diverse dataset with varying difficulty levels. The reinforcement learning stage leverages both outcome and process rewards to guide the model's learning. The backward flow suggests a policy gradient approach, where the model learns from the consequences of its actions. The inclusion of both "Problem-Solving" and "Confirmatory" verification methods indicates a desire for robust and reliable verification capabilities. The SFT mask suggests a method for focusing the model's attention on specific parts of the verification process. Overall, the diagram demonstrates a well-structured and thoughtful approach to building a verification system using reinforcement learning. The use of both problem-solving and confirmatory verification suggests a focus on both the correctness of the answer and the validity of the reasoning process.