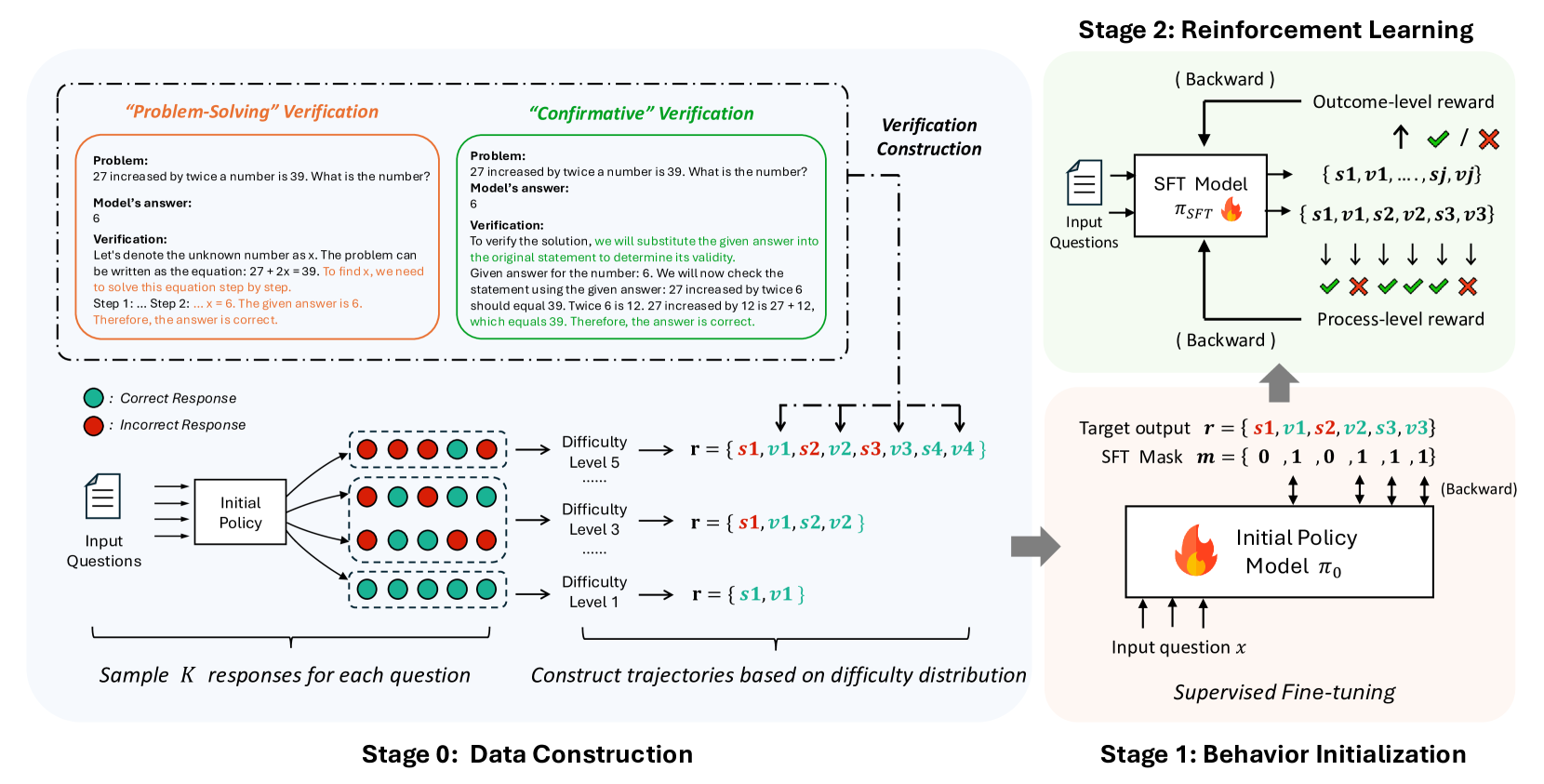
## Diagram: Two-Stage Reinforcement Learning Framework for Educational Model Training
### Overview
The diagram illustrates a two-stage process for training an educational model using reinforcement learning (RL) and supervised fine-tuning (SFT). Stage 0 focuses on data construction through problem-solving verification and trajectory generation, while Stage 1 employs RL with outcome-level and process-level rewards to refine the model via backward passes and supervised fine-tuning.
---
### Components/Axes
#### Stage 0: Data Construction
- **Input Questions**: Textual problems (e.g., "27 increased by twice a number is 39...").
- **Initial Policy**: Generates responses (correct/incorrect) for input questions.
- **Verification Construction**:
- **Problem-Solving Verification**: Checks correctness of answers (e.g., "6" for the math problem).
- **Confirmative Verification**: Validates answers by substitution (e.g., "27 + 12 = 39").
- **Difficulty Levels**: Responses categorized into levels 1, 2, 3, and 5.
- **Trajectory Construction**: Builds sequences of states (`s1, s2, ...`) and values (`v1, v2, ...`) based on difficulty distributions.
#### Stage 1: Behavior Initialization
- **SFT Model**: Processes input questions and generates outputs (`r = {s1,v1,s2,v2,...}`).
- **Outcome-Level Reward**: Binary feedback (✅/❌) for final answers.
- **Process-Level Reward**: Step-by-step validation (✅/❌ for individual steps).
- **Target Output**: Sequences of states and values (`r = {s1,v1,s2,v2,s3,v3}`).
- **Task Mask**: Binary indicators (`m = {0,1,0,1,1,1}`) for selective backpropagation.
- **Supervised Fine-Tuning**: Adjusts the initial policy (`π₀`) using labeled data.
---
### Detailed Analysis
#### Stage 0: Data Construction
1. **Input Questions** are fed into an **Initial Policy** to generate **K responses** per question.
2. Responses are verified:
- **Correct** (green circles) and **Incorrect** (red circles) responses are labeled.
- Difficulty levels are assigned (e.g., Level 5 for complex problems).
3. **Trajectories** are constructed by grouping responses into sequences (`s1,v1,s2,v2,...`) based on difficulty distributions.
#### Stage 1: Behavior Initialization
1. **SFT Model** takes input questions and produces trajectories (`r = {s1,v1,s2,v2,...}`).
2. **Outcome-Level Reward** evaluates final answers (✅/❌).
3. **Process-Level Reward** validates intermediate steps (e.g., "27 + 12 = 39" ✅).
4. **Backward Passes** adjust the SFT model using rewards.
5. **Task Mask** filters which elements (`s1,v1,s2,v2,...`) are updated during backpropagation.
6. **Supervised Fine-Tuning** refines the initial policy (`π₀`) using labeled trajectories.
---
### Key Observations
1. **Difficulty Stratification**: Responses are grouped by difficulty (Levels 1–5), ensuring balanced training across problem complexities.
2. **Dual Reward System**: Combines outcome-level (final answer) and process-level (step-by-step) feedback for robust learning.
3. **Selective Backpropagation**: The task mask (`m = {0,1,0,1,1,1}`) prioritizes updates to specific trajectory elements.
4. **Iterative Refinement**: Stage 0 provides high-quality data, while Stage 1 iteratively improves the model via RL and SFT.
---
### Interpretation
This framework demonstrates a hybrid approach to educational model training:
- **Stage 0** ensures diverse, difficulty-stratified data, critical for capturing edge cases and foundational knowledge.
- **Stage 1** leverages RL to refine reasoning patterns, with process-level rewards addressing common errors (e.g., arithmetic mistakes).
- The **task mask** suggests a focus on high-impact trajectory segments during training, optimizing computational efficiency.
- **Supervised Fine-Tuning** acts as a final calibration step, aligning the model with expert-validated solutions.
The integration of verification methods (problem-solving and confirmative) ensures data quality, while the RL-SFT pipeline enables scalable, error-aware model improvement. This approach could be applied to tutoring systems, automated grading, or adaptive learning platforms.