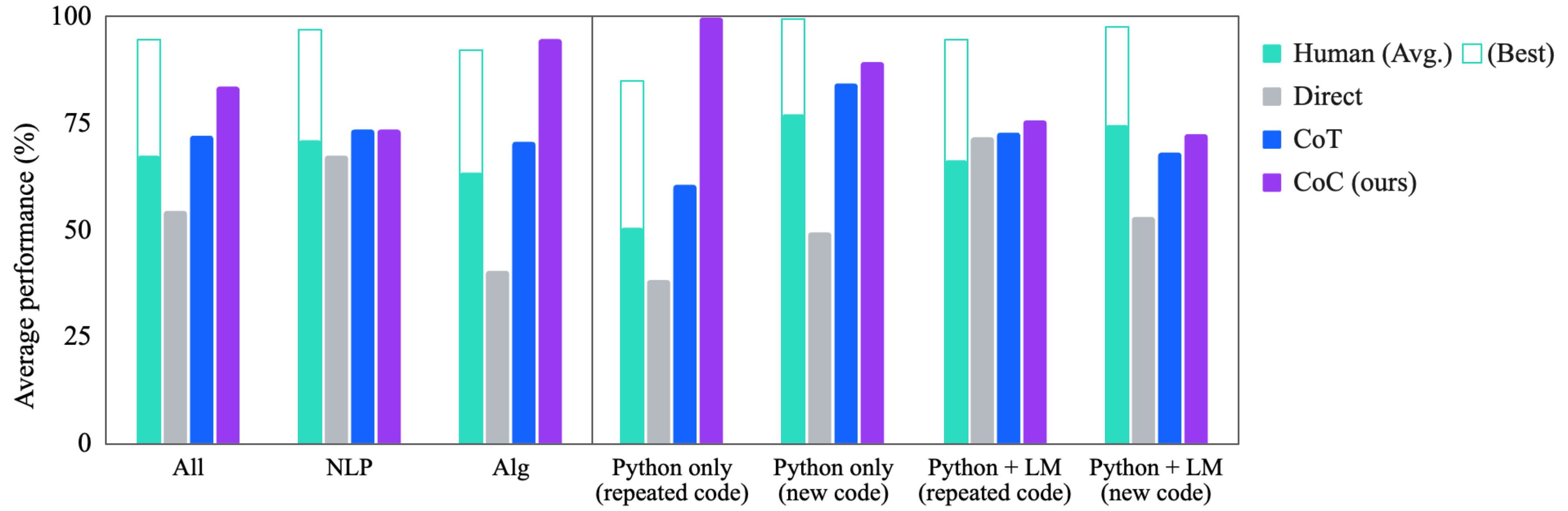
## Bar Chart: Average Performance Comparison Across Methods
### Overview
The chart compares the average performance (%) of four methods (Human, Direct, CoT, CoC) across seven categories: "All", "NLP", "Alg", "Python only (repeated code)", "Python only (new code)", "Python + LM (repeated code)", and "Python + LM (new code)". The legend uses distinct colors for each method, with "Human (Avg.)" in teal, "Direct" in gray, "CoT" in blue, and "CoC (ours)" in purple. The chart emphasizes CoC's dominance in most categories.
### Components/Axes
- **X-axis**: Categories (All, NLP, Alg, Python only (repeated code), Python only (new code), Python + LM (repeated code), Python + LM (new code)).
- **Y-axis**: Average performance (%) from 0 to 100.
- **Legend**: Located on the right, with four methods:
- Teal: Human (Avg.)
- Gray: Direct
- Blue: CoT
- Purple: CoC (ours)
### Detailed Analysis
1. **All**:
- Human (Avg.): ~65%
- Direct: ~55%
- CoT: ~70%
- CoC (ours): ~80%
2. **NLP**:
- Human (Avg.): ~70%
- Direct: ~65%
- CoT: ~75%
- CoC (ours): ~75%
3. **Alg**:
- Human (Avg.): ~60%
- Direct: ~40%
- CoT: ~70%
- CoC (ours): ~95%
4. **Python only (repeated code)**:
- Human (Avg.): ~50%
- Direct: ~40%
- CoT: ~60%
- CoC (ours): ~100%
5. **Python only (new code)**:
- Human (Avg.): ~75%
- Direct: ~50%
- CoT: ~85%
- CoC (ours): ~90%
6. **Python + LM (repeated code)**:
- Human (Avg.): ~65%
- Direct: ~50%
- CoT: ~80%
- CoC (ours): ~75%
7. **Python + LM (new code)**:
- Human (Avg.): ~70%
- Direct: ~55%
- CoT: ~70%
- CoC (ours): ~75%
### Key Observations
- **CoC (ours)** consistently outperforms other methods, achieving the highest scores in 6/7 categories (e.g., 95% in "Alg", 100% in "Python only (repeated code)").
- **Direct** method underperforms across all categories, with the largest gap in "Python only (repeated code)" (~40% vs. CoC's 100%).
- **Human (Avg.)** shows moderate performance, ranging from 50% to 75%, but never exceeds CoC or CoT.
- **CoT** performs second-best in most categories but lags behind CoC in "Alg" and "Python only (repeated code)".
### Interpretation
The data suggests **CoC (ours)** is the most effective method overall, particularly in algorithmic and Python-specific tasks. The **Direct** method's poor performance in "Python only (repeated code)" may indicate limitations in handling repetitive code structures. **Human (Avg.)** provides a baseline but is outperformed by automated methods in most scenarios. The chart highlights CoC's robustness in leveraging both repeated and new code contexts, while CoT remains a strong but secondary alternative. The Direct method's consistent underperformance warrants further investigation into its design or training data.