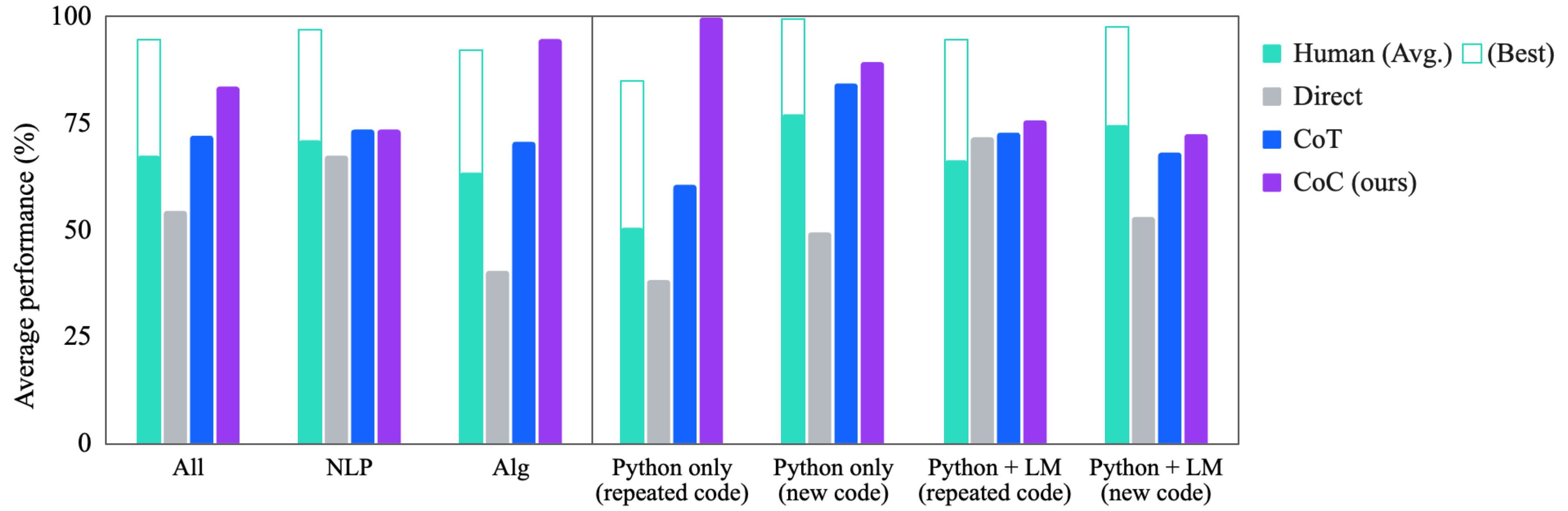
## Bar Chart: Performance Comparison of Different Approaches
### Overview
This bar chart compares the average performance (%) of different approaches – Human (average and best), Direct, Chain-of-Thought (CoT), and CoC (ours) – across various task categories: All, NLP, Alg, Python only (repeated code), Python only (new code), Python + LM (repeated code), and Python + LM (new code). The performance is measured on the y-axis, ranging from 0% to 100%.
### Components/Axes
* **X-axis:** Task Category (All, NLP, Alg, Python only (repeated code), Python only (new code), Python + LM (repeated code), Python + LM (new code)).
* **Y-axis:** Average Performance (%) - Scale from 0 to 100.
* **Legend:**
* Human (Avg.) - Light Cyan
* Human (Best) - Light Green
* Direct - Gray
* CoT - Blue
* CoC (ours) - Purple
### Detailed Analysis
The chart consists of grouped bar plots for each task category. Each group contains five bars representing the performance of the different approaches.
* **All:**
* Human (Avg.): ~63%
* Human (Best): ~95%
* Direct: ~68%
* CoT: ~72%
* CoC (ours): ~82%
* **NLP:**
* Human (Avg.): ~68%
* Human (Best): ~98%
* Direct: ~70%
* CoT: ~74%
* CoC (ours): ~85%
* **Alg:**
* Human (Avg.): ~55%
* Human (Best): ~85%
* Direct: ~62%
* CoT: ~66%
* CoC (ours): ~75%
* **Python only (repeated code):**
* Human (Avg.): ~75%
* Human (Best): ~92%
* Direct: ~80%
* CoT: ~70%
* CoC (ours): ~90%
* **Python only (new code):**
* Human (Avg.): ~72%
* Human (Best): ~96%
* Direct: ~75%
* CoT: ~78%
* CoC (ours): ~94%
* **Python + LM (repeated code):**
* Human (Avg.): ~65%
* Human (Best): ~88%
* Direct: ~68%
* CoT: ~70%
* CoC (ours): ~78%
* **Python + LM (new code):**
* Human (Avg.): ~67%
* Human (Best): ~90%
* Direct: ~70%
* CoT: ~72%
* CoC (ours): ~75%
**Trends:**
* Human (Best) consistently achieves the highest performance across all categories.
* CoC (ours) generally outperforms Direct and CoT across all categories.
* The performance gap between Human (Avg.) and Human (Best) is significant, indicating substantial variability in human performance.
* The "Python only (repeated code)" and "Python only (new code)" categories show the highest performance for all approaches, suggesting that these tasks are relatively easier.
### Key Observations
* CoC (ours) consistently performs close to the Human (Avg.) level, especially in the "Python only" tasks.
* The performance of CoT is generally lower than Direct, except in the "All" category.
* The difference in performance between "repeated code" and "new code" is minimal for CoC (ours), suggesting that the approach is robust to code variations.
### Interpretation
The data suggests that the CoC (ours) approach is a strong contender, achieving performance levels comparable to average human performance, particularly in tasks involving Python code. The consistently high performance of Human (Best) highlights the potential for further improvement in automated approaches. The chart demonstrates the effectiveness of the CoC approach in bridging the gap between automated systems and human-level performance, especially in code-related tasks. The relatively lower performance of CoT compared to Direct suggests that a simpler, more direct approach might be more effective in certain scenarios. The high performance in "Python only" tasks indicates that the models are well-suited for code-related problems. The consistent performance of CoC (ours) across "repeated code" and "new code" suggests that the approach is not overly reliant on memorization or specific code patterns.