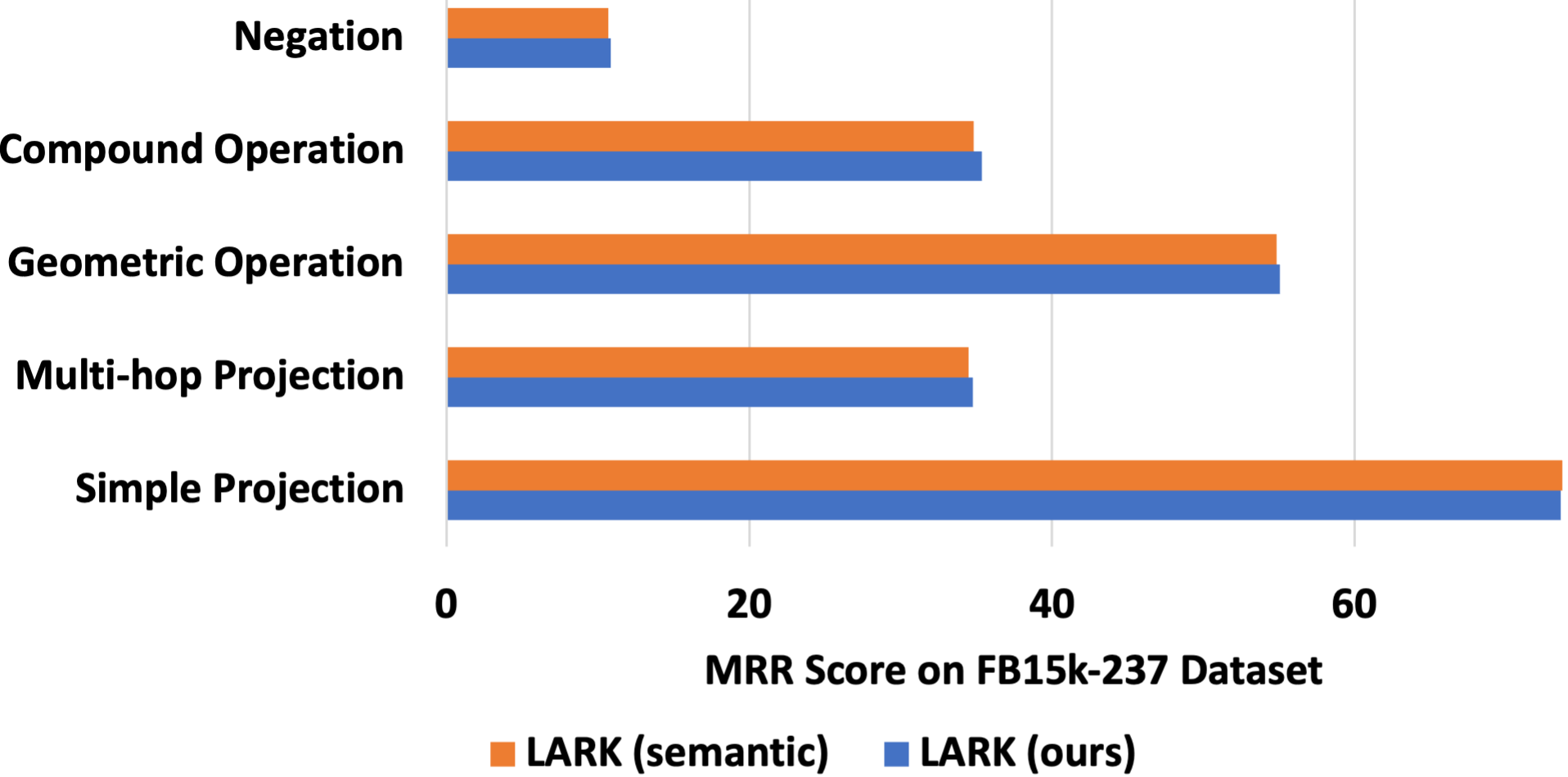
## Horizontal Bar Chart: MRR Score Comparison on FB15k-237 Dataset
### Overview
The image is a horizontal bar chart comparing the MRR (Mean Reciprocal Rank) scores of two models, "LARK (semantic)" and "LARK (ours)", across five different categories: Negation, Compound Operation, Geometric Operation, Multi-hop Projection, and Simple Projection. The x-axis represents the MRR score on the FB15k-237 dataset, ranging from 0 to 60. The y-axis represents the categories.
### Components/Axes
* **X-axis:** MRR Score on FB15k-237 Dataset, with scale markers at 0, 20, 40, and 60.
* **Y-axis:** Categories: Negation, Compound Operation, Geometric Operation, Multi-hop Projection, and Simple Projection.
* **Legend:** Located at the bottom of the chart.
* Orange: LARK (semantic)
* Blue: LARK (ours)
### Detailed Analysis
Here's a breakdown of the MRR scores for each category and model:
* **Negation:**
* LARK (semantic) (Orange): Approximately 10
* LARK (ours) (Blue): Approximately 8
* **Compound Operation:**
* LARK (semantic) (Orange): Approximately 38
* LARK (ours) (Blue): Approximately 35
* **Geometric Operation:**
* LARK (semantic) (Orange): Approximately 60
* LARK (ours) (Blue): Approximately 58
* **Multi-hop Projection:**
* LARK (semantic) (Orange): Approximately 38
* LARK (ours) (Blue): Approximately 35
* **Simple Projection:**
* LARK (semantic) (Orange): Approximately 68
* LARK (ours) (Blue): Approximately 65
### Key Observations
* For all categories, "LARK (semantic)" (orange) has a slightly higher MRR score than "LARK (ours)" (blue).
* The "Simple Projection" category has the highest MRR scores for both models, significantly higher than the other categories.
* The "Negation" category has the lowest MRR scores for both models.
* The difference in MRR scores between the two models is relatively consistent across all categories, with "LARK (semantic)" performing slightly better.
### Interpretation
The chart suggests that "LARK (semantic)" generally outperforms "LARK (ours)" on the FB15k-237 dataset across the tested categories. The "Simple Projection" task appears to be the easiest for both models, while "Negation" is the most challenging. The consistent difference in performance between the two models suggests a systematic advantage for "LARK (semantic)" in this context. The data highlights the relative difficulty of different knowledge graph reasoning tasks, with projection operations being easier than negation or compound operations.