\n
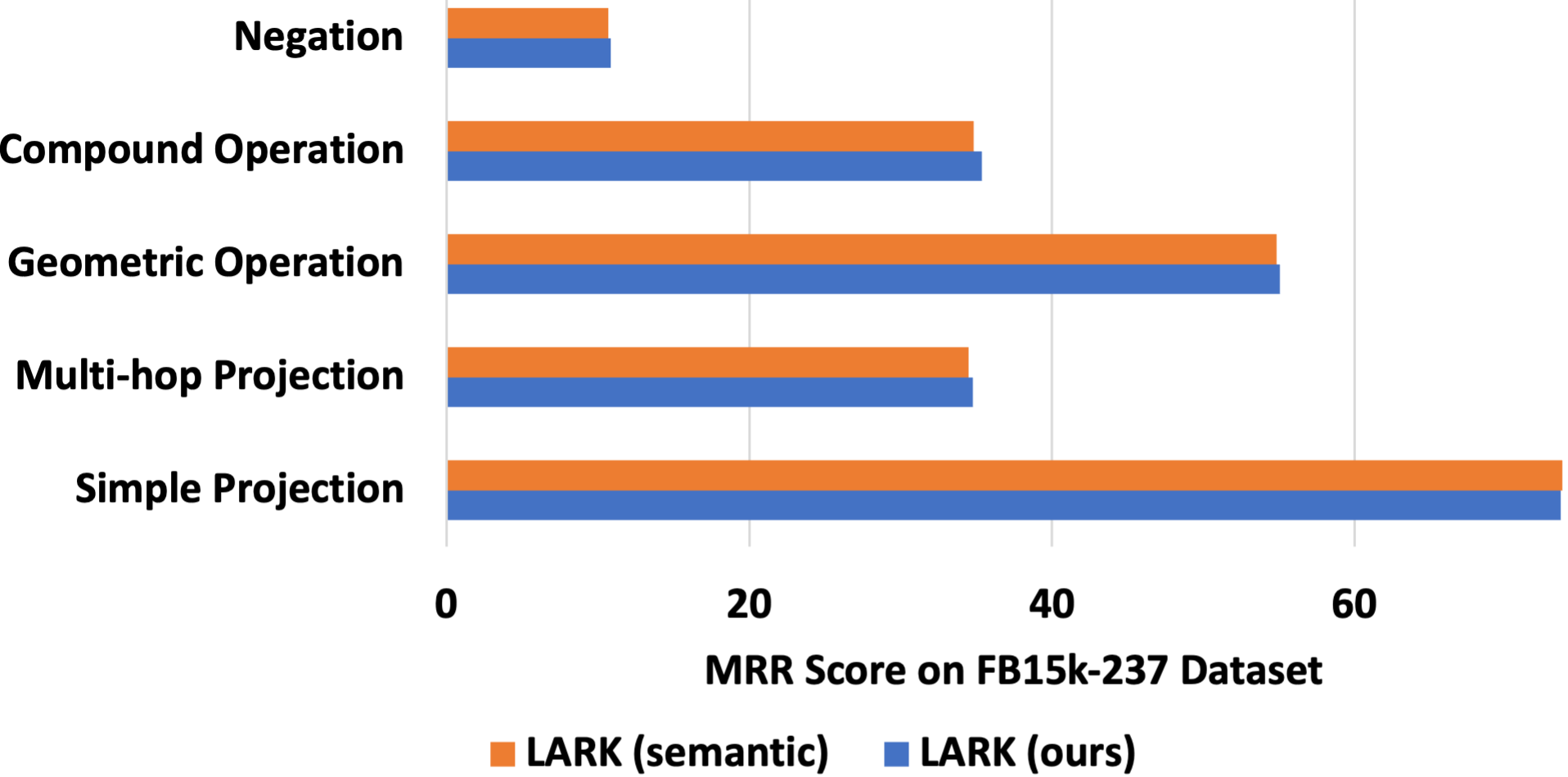
## Bar Chart: MRR Score Comparison on FB15k-237 Dataset
### Overview
This is a horizontal bar chart comparing the Mean Reciprocal Rank (MRR) scores of two methods, "LARK (semantic)" and "LARK (ours)", across five different question types on the FB15k-237 dataset. The chart visually represents the performance of each method for each question type.
### Components/Axes
* **X-axis:** MRR Score on FB15k-237 Dataset, ranging from 0 to 60.
* **Y-axis:** Question Types: Negation, Compound Operation, Geometric Operation, Multi-hop Projection, Simple Projection.
* **Legend:**
* Orange: LARK (semantic)
* Blue: LARK (ours)
* **Chart Title:** Implicitly, the chart title is "MRR Score Comparison".
### Detailed Analysis
The chart consists of five horizontal bars for each method, representing the MRR scores for each question type.
* **Negation:**
* LARK (semantic): Approximately 12.
* LARK (ours): Approximately 10.
* **Compound Operation:**
* LARK (semantic): Approximately 40.
* LARK (ours): Approximately 35.
* **Geometric Operation:**
* LARK (semantic): Approximately 55.
* LARK (ours): Approximately 50.
* **Multi-hop Projection:**
* LARK (semantic): Approximately 40.
* LARK (ours): Approximately 35.
* **Simple Projection:**
* LARK (semantic): Approximately 65.
* LARK (ours): Approximately 60.
The orange bars (LARK semantic) are consistently longer than the blue bars (LARK ours) across all question types, indicating higher MRR scores.
### Key Observations
* "Simple Projection" has the highest MRR scores for both methods.
* "Negation" has the lowest MRR scores for both methods.
* The performance gap between the two methods is relatively consistent across all question types.
* LARK (semantic) consistently outperforms LARK (ours).
### Interpretation
The data suggests that the LARK (semantic) method generally performs better than the LARK (ours) method across all tested question types on the FB15k-237 dataset. The "Simple Projection" question type is the easiest for both methods to solve, while "Negation" presents the greatest challenge. The consistent performance difference between the two methods suggests a fundamental difference in their approach to knowledge graph reasoning. The fact that both methods struggle with "Negation" indicates that handling negation remains a difficult problem in this domain. The chart provides a quantitative comparison of the two methods, allowing for a clear assessment of their relative strengths and weaknesses. The use of the FB15k-237 dataset provides a standardized benchmark for evaluating knowledge graph reasoning models.