## Bar Chart: Model Accuracy Comparison
### Overview
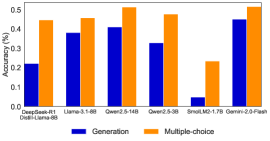
The image is a bar chart comparing the accuracy of different language models on two tasks: generation and multiple-choice. The chart displays the accuracy percentage for each model on each task, allowing for a direct comparison of their performance.
### Components/Axes
* **Y-axis:** Accuracy (%), ranging from 0.0 to 0.5. Increments of 0.1.
* **X-axis:** Language Models:
* DeepSeek-R1 Distill-Llama-8B
* Llama-3.1-8B
* Qwen2.5-14B
* Qwen2.5-3B
* SmolLM2-1.7B
* Gemini-2.0-Flash
* **Legend:** Located at the bottom of the chart.
* Blue: Generation
* Orange: Multiple-choice
### Detailed Analysis
* **DeepSeek-R1 Distill-Llama-8B:**
* Generation (Blue): Accuracy ~0.22
* Multiple-choice (Orange): Accuracy ~0.44
* **Llama-3.1-8B:**
* Generation (Blue): Accuracy ~0.38
* Multiple-choice (Orange): Accuracy ~0.46
* **Qwen2.5-14B:**
* Generation (Blue): Accuracy ~0.41
* Multiple-choice (Orange): Accuracy ~0.51
* **Qwen2.5-3B:**
* Generation (Blue): Accuracy ~0.33
* Multiple-choice (Orange): Accuracy ~0.48
* **SmolLM2-1.7B:**
* Generation (Blue): Accuracy ~0.05
* Multiple-choice (Orange): Accuracy ~0.24
* **Gemini-2.0-Flash:**
* Generation (Blue): Accuracy ~0.45
* Multiple-choice (Orange): Accuracy ~0.48
### Key Observations
* For all models, the multiple-choice accuracy is higher than the generation accuracy.
* Qwen2.5-14B has the highest multiple-choice accuracy (~0.51).
* SmolLM2-1.7B has the lowest accuracy for both generation and multiple-choice tasks.
* Gemini-2.0-Flash has the highest generation accuracy (~0.45).
### Interpretation
The data suggests that all the language models perform better on multiple-choice tasks compared to generation tasks. This could be due to the nature of the tasks, where multiple-choice provides a set of options to choose from, while generation requires the model to produce text from scratch. The Qwen2.5-14B model appears to be the most accurate on multiple-choice, while Gemini-2.0-Flash is the most accurate on generation. SmolLM2-1.7B lags significantly behind the other models in both tasks, indicating a potential area for improvement. The difference in performance between the models highlights the impact of model architecture, training data, and other factors on the accuracy of language models.