\n
## Bar Chart: Model Accuracy Comparison
### Overview
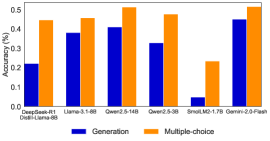
The image presents a bar chart comparing the accuracy of several language models on two different task types: "Generation" and "Multiple-choice". The accuracy is measured in percentage (%). The chart displays the performance of DeepSeek-RL1, Llama-3.1-6B, Qwen-2.5-14B, Qwen-2.5-3B, SmalM2-1.7B, and Gemini-2.0-Flash models.
### Components/Axes
* **X-axis:** Model Names - DeepSeek-RL1, Llama-3.1-6B, Qwen-2.5-14B, Qwen-2.5-3B, SmalM2-1.7B, Gemini-2.0-Flash.
* **Y-axis:** Accuracy (%) - Scale ranges from 0.0 to 0.5, with increments of 0.1.
* **Legend:**
* Dark Blue: Generation
* Orange: Multiple-choice
* **Chart Title:** Not explicitly present, but the chart's content suggests a comparison of model accuracy.
### Detailed Analysis
The chart consists of paired bars for each model, representing its accuracy in "Generation" and "Multiple-choice" tasks.
* **DeepSeek-RL1:**
* Generation: Approximately 0.38 (±0.02)
* Multiple-choice: Approximately 0.45 (±0.02)
* **Llama-3.1-6B:**
* Generation: Approximately 0.39 (±0.02)
* Multiple-choice: Approximately 0.47 (±0.02)
* **Qwen-2.5-14B:**
* Generation: Approximately 0.41 (±0.02)
* Multiple-choice: Approximately 0.52 (±0.02)
* **Qwen-2.5-3B:**
* Generation: Approximately 0.32 (±0.02)
* Multiple-choice: Approximately 0.48 (±0.02)
* **SmalM2-1.7B:**
* Generation: Approximately 0.05 (±0.01)
* Multiple-choice: Approximately 0.23 (±0.02)
* **Gemini-2.0-Flash:**
* Generation: Approximately 0.44 (±0.02)
* Multiple-choice: Approximately 0.50 (±0.02)
The orange bars (Multiple-choice) generally trend higher than the blue bars (Generation) across all models.
### Key Observations
* SmalM2-1.7B exhibits significantly lower accuracy in both tasks compared to other models.
* Qwen-2.5-14B demonstrates the highest accuracy in the Multiple-choice task.
* The difference in accuracy between Generation and Multiple-choice is more pronounced for some models (e.g., SmalM2-1.7B) than others.
* The models generally perform better on the Multiple-choice task than on the Generation task.
### Interpretation
The data suggests that the evaluated language models are generally more proficient at Multiple-choice question answering than at open-ended text Generation. The large discrepancy in SmalM2-1.7B's performance indicates it may be less capable or require further optimization for these tasks. The higher accuracy of Qwen-2.5-14B in Multiple-choice suggests that model size or architecture plays a role in performance. The consistent trend of higher Multiple-choice accuracy could be due to the constrained nature of the task, making it easier for the models to identify the correct answer compared to generating coherent and accurate text. The chart provides a comparative overview of model capabilities, highlighting strengths and weaknesses in different task settings.