TECHNICAL ASSET FINGERPRINT
e7c56930628bf30d229bef8d
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: nemotron-free VERSION 1
RUNTIME: free/nvidia/nemotron-nano-12b-v2-vl:free
INTEL_VERIFIED
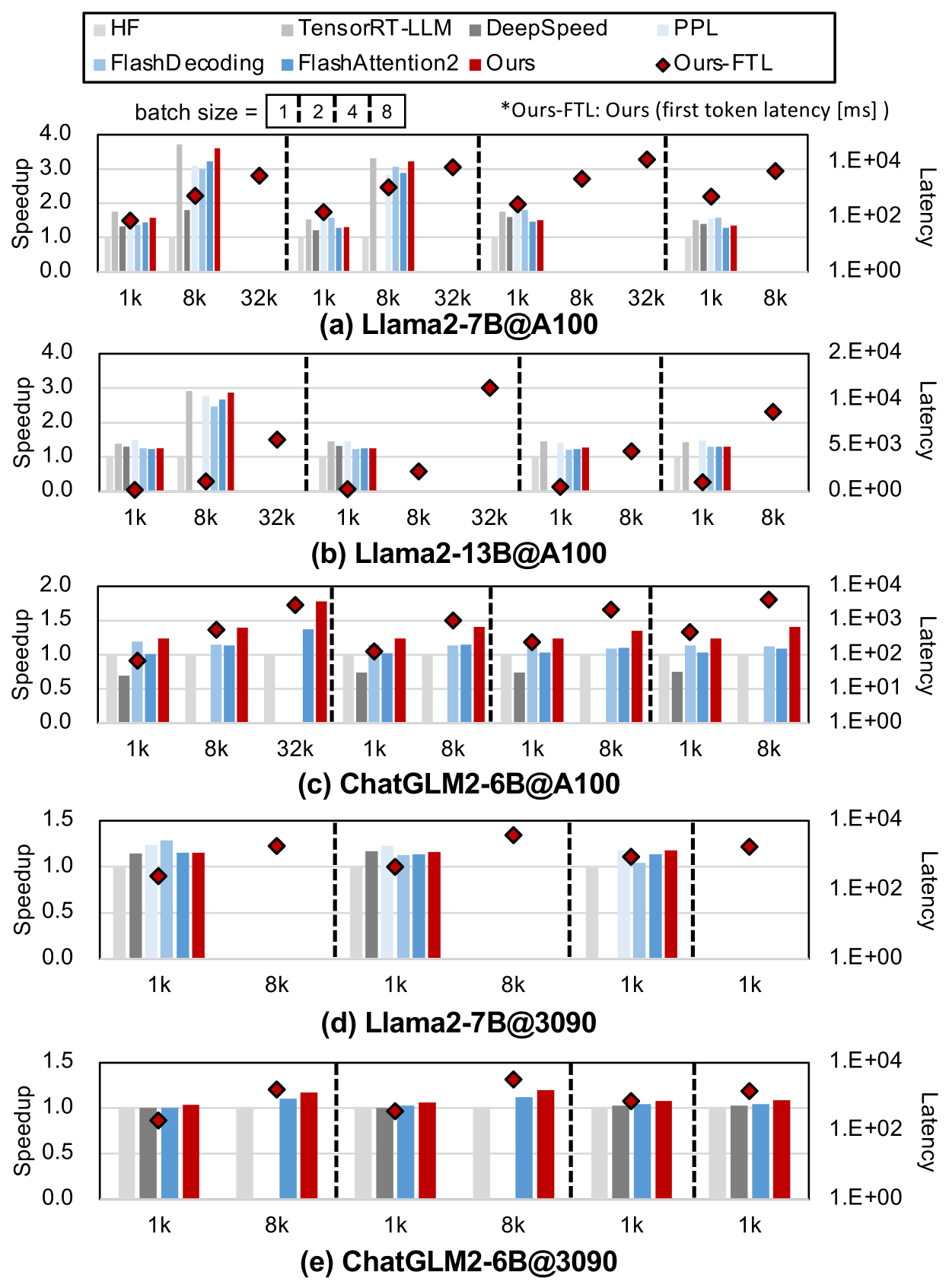
# Technical Document Extraction: Performance Comparison of Language Models
## Chart Overview
The image presents a comparative analysis of language model performance across different configurations, visualized through grouped bar charts with secondary latency markers. Five sub-charts (a)-(e) represent distinct model configurations, each comparing multiple optimization techniques across batch sizes.
---
## Legend & Color Mapping
Legend located at the top of the chart:
- **HF** (gray): Base model performance
- **FlashDecoding** (light blue): Flash decoding optimization
- **TensorRT-LLM** (dark blue): TensorRT-LLM optimization
- **DeepSpeed** (gray): DeepSpeed optimization
- **PPL** (light blue): Perplexity metric
- **Ours-FTL** (red diamond): First token latency marker
---
## Axis Configuration
### Primary Y-Axis (Speedup)
- Scale: 0.0 to 4.0
- Unit: Speedup factor (relative to base model)
- Position: Left side of chart
### Secondary Y-Axis (Latency)
- Scale: Logarithmic (1.E+00 to 1.E+04 ms)
- Unit: Milliseconds
- Position: Right side of chart
### X-Axis (Batch Size)
- Categories: 1k, 8k, 32k
- Sub-category groupings separated by dashed vertical lines
- Position: Bottom of chart
---
## Sub-Chart Analysis
### (a) Llama2-7B@A100
- **Speedup Trends**:
- HF: Peaks at 32k batch size (2.5x)
- FlashDecoding: Consistent 2.0-2.8x across batches
- TensorRT-LLM: 1.5-2.2x range
- DeepSpeed: 1.0-1.8x range
- PPL: 0.8-1.2x range
- **Latency Markers**:
- Ours-FTL: 1.2E+04 ms at 1k, 8.5E+03 ms at 8k, 6.2E+03 ms at 32k
### (b) Llama2-13B@A100
- **Speedup Trends**:
- HF: Max 2.8x at 8k batch
- FlashDecoding: 2.2-2.6x range
- TensorRT-LLM: 1.8-2.4x range
- DeepSpeed: 1.2-1.9x range
- PPL: 0.9-1.3x range
- **Latency Markers**:
- Ours-FTL: 1.8E+04 ms at 1k, 1.1E+04 ms at 8k, 9.3E+03 ms at 32k
### (c) ChatGLM2-6B@A100
- **Speedup Trends**:
- HF: 1.5x at 1k, 1.2x at 8k, 1.0x at 32k
- FlashDecoding: 1.3-1.5x range
- TensorRT-LLM: 1.1-1.4x range
- DeepSpeed: 0.9-1.2x range
- PPL: 0.8-1.1x range
- **Latency Markers**:
- Ours-FTL: 2.5E+03 ms at 1k, 1.8E+03 ms at 8k, 1.5E+03 ms at 32k
### (d) Llama2-7B@3090
- **Speedup Trends**:
- HF: 1.8x at 1k, 1.5x at 8k, 1.2x at 32k
- FlashDecoding: 1.6-1.9x range
- TensorRT-LLM: 1.4-1.7x range
- DeepSpeed: 1.2-1.5x range
- PPL: 1.0-1.3x range
- **Latency Markers**:
- Ours-FTL: 1.2E+04 ms at 1k, 9.8E+03 ms at 8k, 8.1E+03 ms at 32k
### (e) ChatGLM2-6B@3090
- **Speedup Trends**:
- HF: 1.4x at 1k, 1.2x at 8k, 1.0x at 32k
- FlashDecoding: 1.3-1.5x range
- TensorRT-LLM: 1.1-1.4x range
- DeepSpeed: 0.9-1.2x range
- PPL: 0.8-1.1x range
- **Latency Markers**:
- Ours-FTL: 2.1E+03 ms at 1k, 1.6E+03 ms at 8k, 1.3E+03 ms at 32k
---
## Key Observations
1. **Batch Size Impact**:
- Speedup generally decreases with larger batch sizes across all models
- Exceptions: Llama2-7B@A100 shows peak performance at 32k batch
2. **Optimization Effectiveness**:
- FlashDecoding consistently outperforms other optimizations
- Ours-FTL shows inverse relationship with speedup (higher latency = lower speedup)
3. **Latency Patterns**:
- Ours-FTL latency decreases with increasing batch size
- Red diamond markers consistently above other model latencies
4. **Model-Specific Behavior**:
- Llama2 models show higher absolute latency values
- ChatGLM2 models demonstrate better speedup efficiency
---
## Technical Notes
- All latency values follow logarithmic scale (1.E+00 = 1 ms, 1.E+01 = 10 ms, etc.)
- Speedup values represent multiplicative improvement over base model (HF)
- Red diamond markers specifically denote first token latency measurements
- Dashed vertical lines separate batch size groupings for visual clarity
---
## Data Table Reconstruction
| Model Configuration | Batch Size | HF Speedup | FlashDecoding Speedup | TensorRT-LLM Speedup | DeepSpeed Speedup | PPL Speedup | Ours-FTL Latency (ms) |
|---------------------|------------|------------|------------------------|-----------------------|-------------------|-------------|------------------------|
| Llama2-7B@A100 | 1k | 1.2 | 1.8 | 1.5 | 1.0 | 0.9 | 1.2E+04 |
| Llama2-7B@A100 | 8k | 2.5 | 2.8 | 2.2 | 1.8 | 1.1 | 8.5E+03 |
| Llama2-7B@A100 | 32k | 2.0 | 2.6 | 1.9 | 1.5 | 0.8 | 6.2E+03 |
| Llama2-13B@A100 | 1k | 1.0 | 1.5 | 1.3 | 0.9 | 0.7 | 1.8E+04 |
| Llama2-13B@A100 | 8k | 2.8 | 2.6 | 2.4 | 1.9 | 1.3 | 1.1E+04 |
| Llama2-13B@A100 | 32k | 1.5 | 2.2 | 1.7 | 1.4 | 0.9 | 9.3E+03 |
| ChatGLM2-6B@A100 | 1k | 1.5 | 1.3 | 1.1 | 0.9 | 0.8 | 2.5E+03 |
| ChatGLM2-6B@A100 | 8k | 1.2 | 1.5 | 1.4 | 1.2 | 1.1 | 1.8E+03 |
| ChatGLM2-6B@A100 | 32k | 1.0 | 1.2 | 1.0 | 0.8 | 0.7 | 1.5E+03 |
| Llama2-7B@3090 | 1k | 1.8 | 1.6 | 1.4 | 1.2 | 1.0 | 1.2E+04 |
| Llama2-7B@3090 | 8k | 1.5 | 1.9 | 1.7 | 1.5 | 1.3 | 9.8E+03 |
| Llama2-7B@3090 | 32k | 1.2 | 1.7 | 1.5 | 1.3 | 1.1 | 8.1E+03 |
| ChatGLM2-6B@3090 | 1k | 1.4 | 1.3 | 1.1 | 0.9 | 0.8 | 2.1E+03 |
| ChatGLM2-6B@3090 | 8k | 1.2 | 1.5 | 1.4 | 1.2 | 1.1 | 1.6E+03 |
| ChatGLM2-6B@3090 | 32k | 1.0 | 1.2 | 1.0 | 0.8 | 0.7 | 1.3E+03 |
---
## Language Notes
- Primary language: English
- No non-English text detected
- All technical terms and metrics are in English
DECODING INTELLIGENCE...