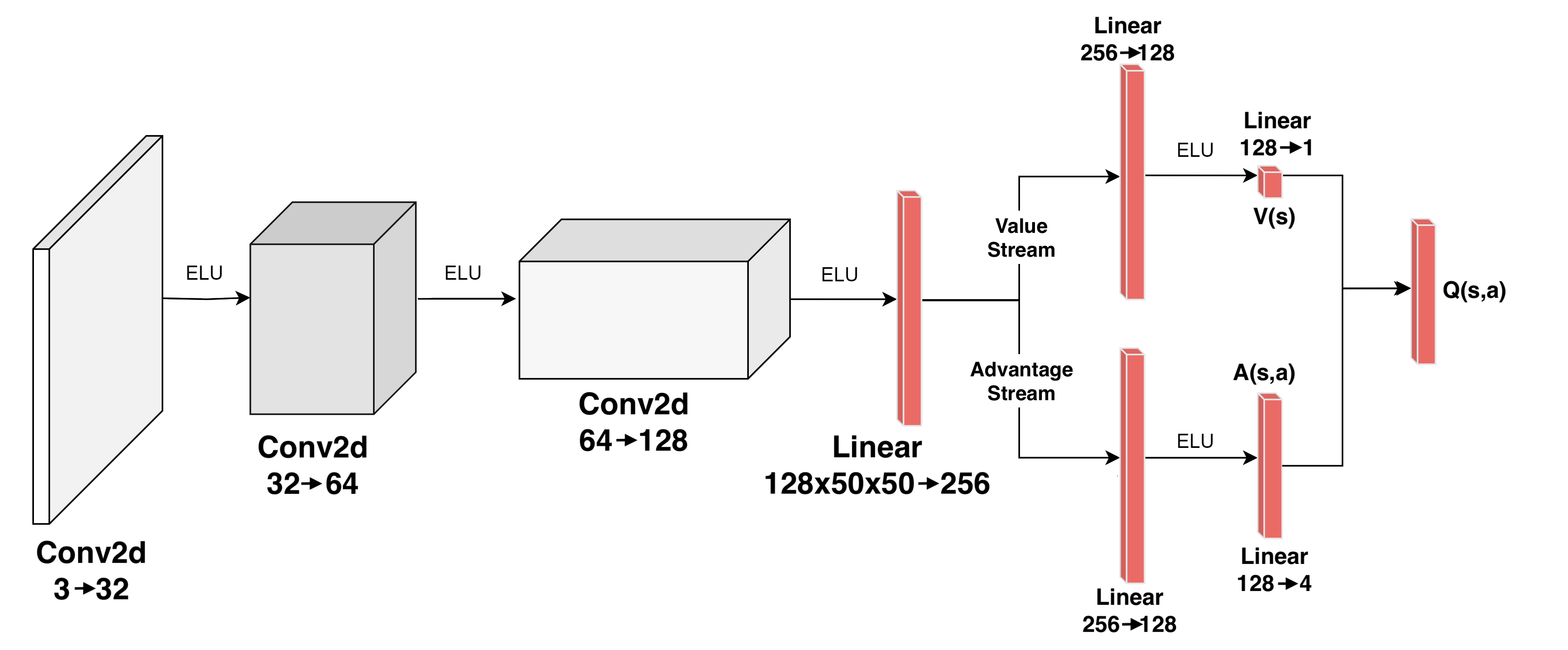
## Diagram: Deep Q-Network (DQN) Architecture
### Overview
The diagram illustrates a neural network architecture for a Deep Q-Network (DQN), commonly used in reinforcement learning. It includes convolutional layers, linear layers, activation functions (ELU), and streams for value and advantage estimation. The flow progresses from input to output through sequential transformations.
### Components/Axes
- **Input Layer**:
- **Conv2d**: `3 → 32` (3 input channels to 32 output channels).
- **Hidden Layers**:
- **Conv2d**: `32 → 64` (second convolutional layer).
- **Linear**: `128x50x50 → 256` (flattened convolutional output to 256 units).
- **Streams**:
- **Value Stream**:
- **Linear**: `256 → 128` → **ELU** → **Linear**: `128 → 1` (outputs value function `V(s)`).
- **Advantage Stream**:
- **Linear**: `256 → 128` → **ELU** → **Linear**: `128 → 4` (outputs advantage function `A(s,a)`).
- **Output**:
- **Q(s,a)**: Combines `V(s)` and `A(s,a)` via addition (`Q(s,a) = V(s) + A(s,a)`).
### Detailed Analysis
1. **Input Processing**:
- The input (e.g., raw pixel data) passes through two `Conv2d` layers with increasing channel depth (3 → 32 → 64), likely for feature extraction.
2. **Flattening**:
- The output of the second `Conv2d` (spatial dimensions 128x50x50) is flattened into a 1D vector of 256 units via a linear layer.
3. **Stream Splitting**:
- The 256-unit vector splits into two parallel streams:
- **Value Stream**: Predicts the state value `V(s)` (single output unit).
- **Advantage Stream**: Predicts the advantage `A(s,a)` (4 output units, likely for discrete actions).
4. **Activation Functions**:
- ELU (Exponential Linear Unit) is applied after each linear layer to introduce non-linearity.
5. **Output Fusion**:
- The final Q-value `Q(s,a)` is computed by adding the value function `V(s)` and advantage function `A(s,a)`.
### Key Observations
- **Architecture Type**: Combines convolutional layers for spatial feature extraction with linear layers for value/advantage estimation, typical of DQN with A2C (Advantage Actor-Critic) enhancements.
- **Output Dimensions**:
- `V(s)` outputs a scalar (1 unit), representing the expected return for state `s`.
- `A(s,a)` outputs 4 units, likely corresponding to discrete actions (e.g., up, down, left, right).
- **ELU Usage**: Ensures smooth gradients during training, avoiding dead neurons.
### Interpretation
This architecture is designed for reinforcement learning tasks requiring spatial input (e.g., Atari games). The separation into value and advantage streams improves training stability by decoupling state-value estimation from action-specific advantages. The final Q-value fusion enables policy optimization via methods like Q-learning or policy gradients. The use of `Conv2d` layers suggests compatibility with image-based inputs, while the linear layers handle high-dimensional state representations.
No numerical data or trends are present in the diagram; it focuses on architectural components and flow.