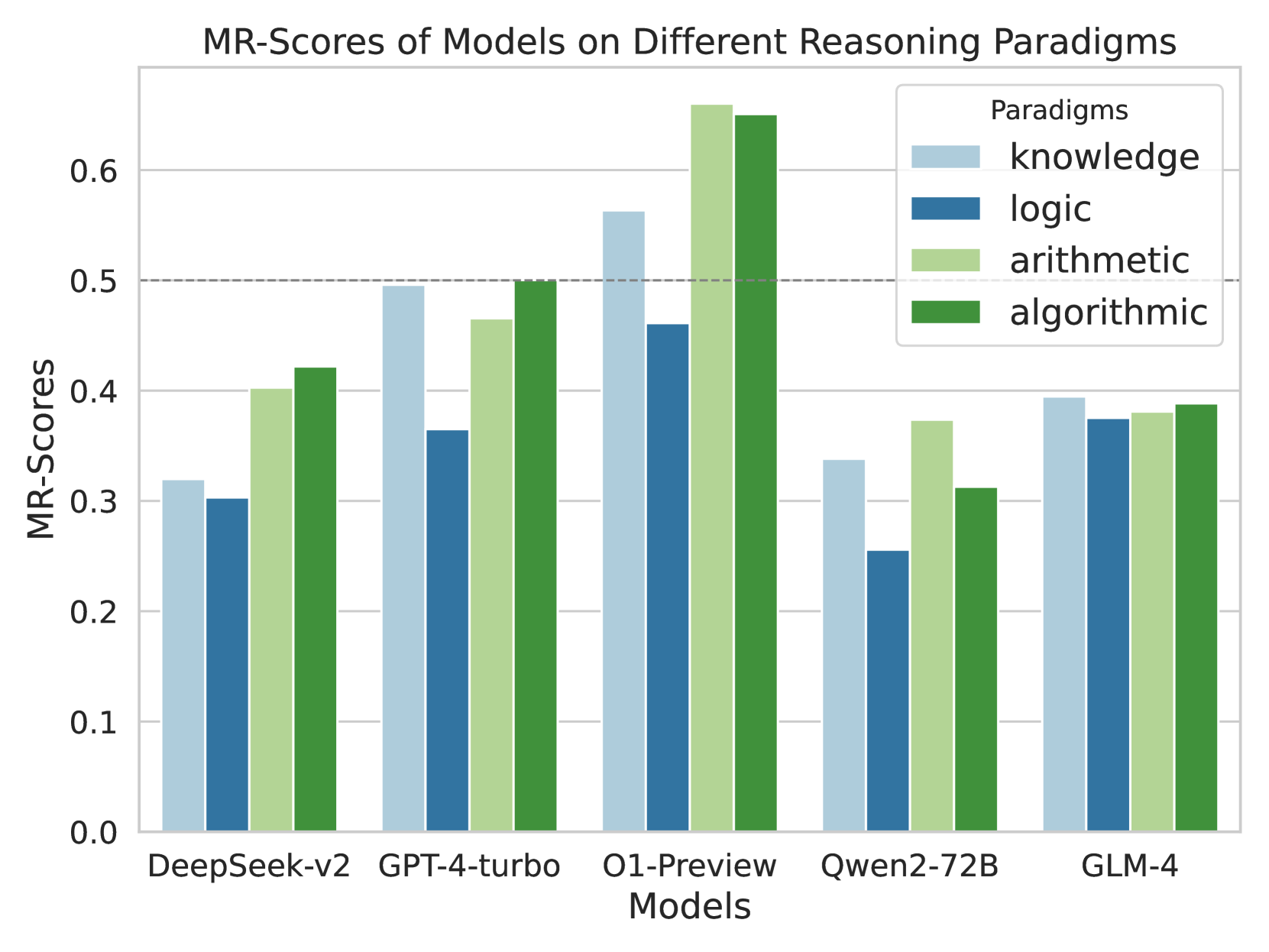
## Grouped Bar Chart: MR-Scores of Models on Different Reasoning Paradigms
### Overview
This is a grouped bar chart comparing the performance of five different AI models across four distinct reasoning paradigms. The performance metric is the "MR-Score," with values ranging from 0.0 to just above 0.6. The chart visually contrasts model strengths and weaknesses across knowledge, logic, arithmetic, and algorithmic reasoning tasks.
### Components/Axes
* **Chart Title:** "MR-Scores of Models on Different Reasoning Paradigms" (centered at the top).
* **Y-Axis:** Labeled "MR-Scores". The scale runs from 0.0 to 0.6 with major gridlines at intervals of 0.1 (0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6). A dashed horizontal reference line is present at the 0.5 mark.
* **X-Axis:** Labeled "Models". It lists five distinct models: "DeepSeek-v2", "GPT-4-turbo", "O1-Preview", "Qwen2-72B", and "GLM-4".
* **Legend:** Located in the top-right corner of the plot area, titled "Paradigms". It defines the color coding for the four reasoning paradigms:
* **knowledge:** Light blue
* **logic:** Dark blue
* **arithmetic:** Light green
* **algorithmic:** Dark green
### Detailed Analysis
The chart presents the MR-Scores for each model across the four paradigms. Values are approximate based on visual alignment with the y-axis gridlines.
**1. DeepSeek-v2**
* **knowledge (light blue):** ~0.32
* **logic (dark blue):** ~0.30
* **arithmetic (light green):** ~0.40
* **algorithmic (dark green):** ~0.42
* *Trend:* Scores increase from logic (lowest) to knowledge, then to arithmetic and algorithmic (highest).
**2. GPT-4-turbo**
* **knowledge (light blue):** ~0.50 (touches the dashed reference line)
* **logic (dark blue):** ~0.36
* **arithmetic (light green):** ~0.46
* **algorithmic (dark green):** ~0.50
* *Trend:* Knowledge and algorithmic are tied for highest. Logic is the lowest.
**3. O1-Preview**
* **knowledge (light blue):** ~0.56
* **logic (dark blue):** ~0.46
* **arithmetic (light green):** ~0.66 (the highest single bar in the chart)
* **algorithmic (dark green):** ~0.65
* *Trend:* This model shows the highest overall performance. Arithmetic is the peak, followed closely by algorithmic. Logic is the lowest but still relatively high compared to other models' logic scores.
**4. Qwen2-72B**
* **knowledge (light blue):** ~0.34
* **logic (dark blue):** ~0.25 (the lowest single bar in the chart)
* **arithmetic (light green):** ~0.37
* **algorithmic (dark green):** ~0.31
* *Trend:* Arithmetic is the highest. Logic is notably the lowest, creating a significant gap.
**5. GLM-4**
* **knowledge (light blue):** ~0.39
* **logic (dark blue):** ~0.37
* **arithmetic (light green):** ~0.38
* **algorithmic (dark green):** ~0.39
* *Trend:* Scores are very tightly clustered, showing the most balanced performance across all four paradigms among the models shown.
### Key Observations
* **Top Performer:** O1-Preview achieves the highest scores in three of the four paradigms (knowledge, arithmetic, algorithmic) and is second in logic.
* **Paradigm Difficulty:** Across most models, the "logic" paradigm (dark blue bars) tends to yield the lowest or among the lowest scores, suggesting it may be the most challenging task set for these models.
* **Model Specialization:** Models show different strength profiles. O1-Preview excels in arithmetic/algorithmic. GPT-4-turbo is strong in knowledge/algorithmic. Qwen2-72B has a pronounced weakness in logic. GLM-4 is the most generalist.
* **Score Range:** The majority of scores fall between 0.25 and 0.55, with O1-Preview's arithmetic score being a clear outlier above 0.6.
### Interpretation
This chart provides a comparative benchmark of AI model reasoning capabilities. The data suggests that reasoning performance is not monolithic; a model's proficiency varies significantly depending on the type of reasoning required (knowledge recall, logical deduction, arithmetic calculation, or algorithmic problem-solving).
The standout performance of O1-Preview, particularly in arithmetic and algorithmic tasks, indicates a potential architectural or training advantage in handling structured, step-by-step computational reasoning. Conversely, the consistent relative weakness in "logic" across models points to a common challenge in the field, possibly related to handling abstract relational reasoning or avoiding fallacies.
The balanced profile of GLM-4 is noteworthy, as it suggests a more uniform capability across diverse reasoning types, which could be advantageous for general-purpose applications. The chart effectively communicates that choosing the "best" model depends heavily on the specific reasoning task at hand. The dashed line at 0.5 serves as a visual benchmark, which only O1-Preview and GPT-4-turbo (in two paradigms each) consistently meet or exceed.