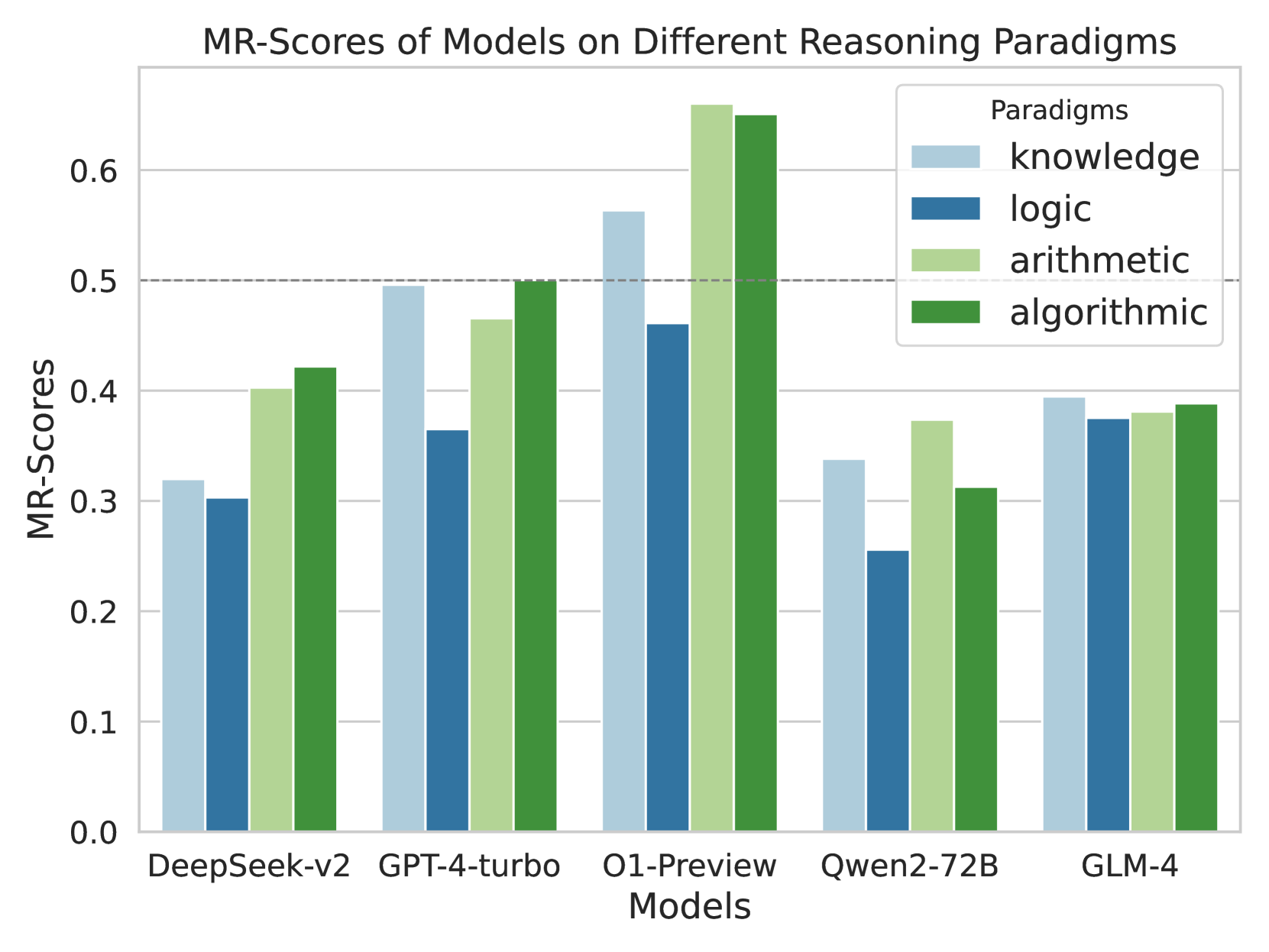
## Bar Chart: MR-Scores of Models on Different Reasoning Paradigms
### Overview
The chart compares the Mean Reciprocal Rank (MRR) scores of five AI models (DeepSeek-v2, GPT-4-turbo, O1-Preview, Qwen2-72B, GLM-4) across four reasoning paradigms: knowledge, logic, arithmetic, and algorithmic. MRR scores range from 0.0 to 0.7, with higher values indicating better performance. The chart uses grouped bars to visualize performance differences between models and paradigms.
### Components/Axes
- **X-axis**: Models (DeepSeek-v2, GPT-4-turbo, O1-Preview, Qwen2-72B, GLM-4)
- **Y-axis**: MR-Scores (0.0 to 0.7 in increments of 0.1)
- **Legend**:
- Light blue: knowledge
- Dark blue: logic
- Light green: arithmetic
- Dark green: algorithmic
- **Key markers**: Dashed horizontal line at ~0.5 (reference threshold)
### Detailed Analysis
1. **DeepSeek-v2**:
- Knowledge: ~0.32
- Logic: ~0.30
- Arithmetic: ~0.40
- Algorithmic: ~0.42
2. **GPT-4-turbo**:
- Knowledge: ~0.50
- Logic: ~0.37
- Arithmetic: ~0.47
- Algorithmic: ~0.50
3. **O1-Preview**:
- Knowledge: ~0.56
- Logic: ~0.47
- Arithmetic: ~0.67
- Algorithmic: ~0.65
4. **Qwen2-72B**:
- Knowledge: ~0.34
- Logic: ~0.25
- Arithmetic: ~0.38
- Algorithmic: ~0.31
5. **GLM-4**:
- Knowledge: ~0.39
- Logic: ~0.38
- Arithmetic: ~0.38
- Algorithmic: ~0.39
### Key Observations
- **O1-Preview** dominates across all paradigms, with arithmetic (~0.67) and algorithmic (~0.65) scores exceeding the 0.5 threshold.
- **Qwen2-72B** underperforms significantly, particularly in logic (~0.25) and algorithmic (~0.31) paradigms.
- **GPT-4-turbo** and **GLM-4** show mid-range performance, with GPT-4-turbo excelling in knowledge (~0.50) and GLM-4 showing balanced scores (~0.38-0.39).
- Arithmetic and algorithmic paradigms generally receive higher scores than knowledge and logic across models.
### Interpretation
The data suggests **O1-Preview** is the most robust model for reasoning tasks, particularly in arithmetic and algorithmic domains. Its high scores may reflect specialized training or architecture optimizations. Conversely, **Qwen2-72B**'s low logic score (~0.25) indicates potential weaknesses in deductive reasoning, possibly due to training data limitations or model design constraints.
The consistent outperformance of arithmetic and algorithmic paradigms across models implies these tasks align better with typical AI training objectives (e.g., pattern recognition in structured data). Knowledge and logic paradigms show more variability, suggesting challenges in handling unstructured information or complex logical inference.
Notably, **GPT-4-turbo**'s high knowledge score (~0.50) despite lower logic performance highlights a potential trade-off between breadth (knowledge) and depth (logic) in current models. This could reflect prioritization of general knowledge over rigorous logical consistency in training objectives.