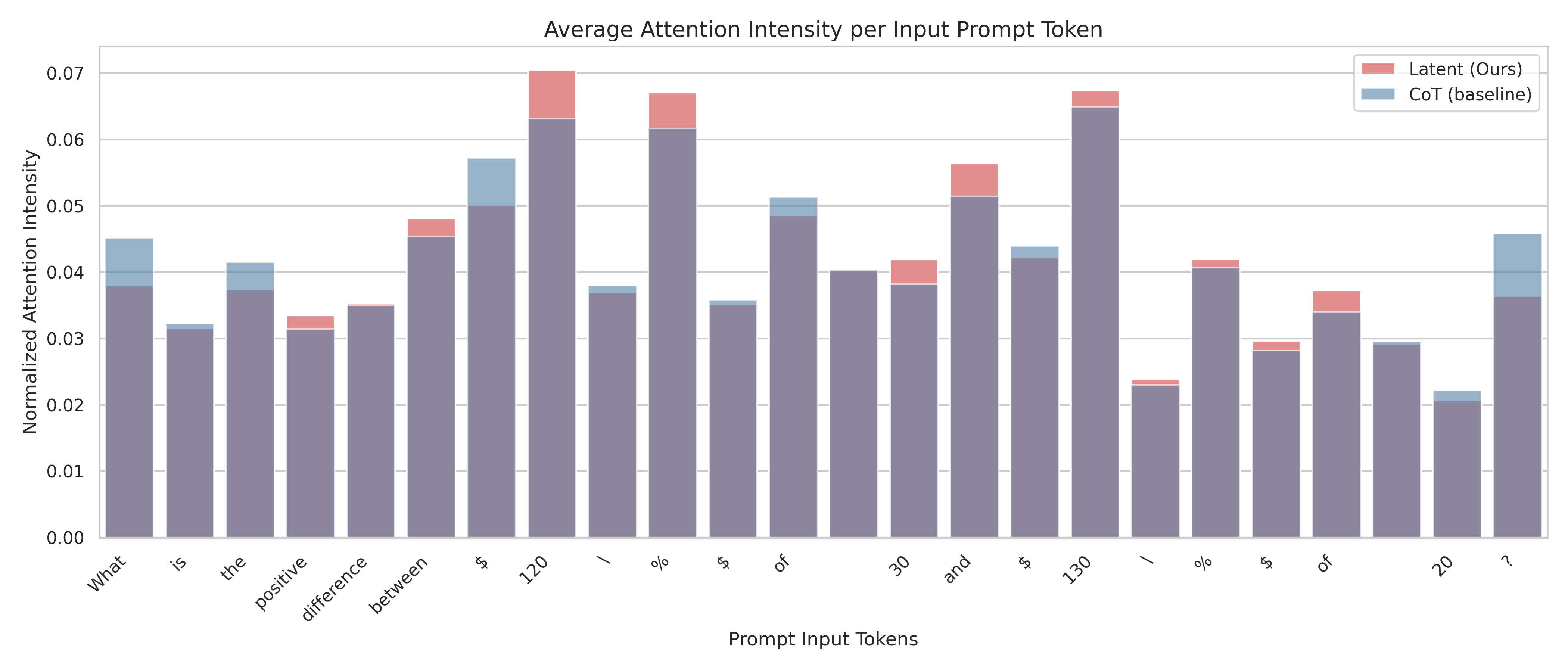
## Bar Chart: Average Attention Intensity per Input Prompt Token
### Overview
The chart compares normalized attention intensity across prompt input tokens for two methods: Latent (Ours) and CoT (baseline). Bars are grouped by token, with Latent represented in red and CoT in blue. The y-axis scales from 0.00 to 0.07, showing relative attention weights.
### Components/Axes
- **X-axis (Prompt Input Tokens)**:
Tokens include:
`What`, `is`, `the`, `positive`, `difference`, `between`, `$`, `120`, `/`, `%`, `of`, `and`, `$`, `130`, `?`, `20`.
Some tokens (e.g., `$`, `%`, `of`) appear multiple times.
- **Y-axis (Normalized Attention Intensity)**:
Scale from 0.00 to 0.07 in increments of 0.01.
- **Legend**:
- Red: Latent (Ours)
- Blue: CoT (baseline)
Positioned in the top-right corner.
### Detailed Analysis
- **Token-Specific Values** (approximate):
- `What`: Latent ≈ 0.038, CoT ≈ 0.006
- `is`: Latent ≈ 0.031, CoT ≈ 0.002
- `the`: Latent ≈ 0.037, CoT ≈ 0.004
- `positive`: Latent ≈ 0.032, CoT ≈ 0.003
- `difference`: Latent ≈ 0.035, CoT ≈ 0.002
- `between`: Latent ≈ 0.046, CoT ≈ 0.008
- `$` (first occurrence): Latent ≈ 0.050, CoT ≈ 0.007
- `120`: Latent ≈ 0.063, CoT ≈ 0.005
- `/`: Latent ≈ 0.037, CoT ≈ 0.003
- `%`: Latent ≈ 0.062, CoT ≈ 0.004
- `of` (first occurrence): Latent ≈ 0.049, CoT ≈ 0.006
- `and`: Latent ≈ 0.052, CoT ≈ 0.005
- `$` (second occurrence): Latent ≈ 0.041, CoT ≈ 0.002
- `130`: Latent ≈ 0.065, CoT ≈ 0.004
- `?`: Latent ≈ 0.036, CoT ≈ 0.003
- `20`: Latent ≈ 0.023, CoT ≈ 0.001
### Key Observations
1. **Latent Dominates**: Latent consistently shows higher attention intensity than CoT across most tokens.
2. **Peaks for Numerical Tokens**:
- `120` and `130` exhibit the highest Latent attention (≈0.063–0.065).
- `%` also shows strong Latent focus (≈0.062).
3. **Low Attention for Function Words**:
- Tokens like `is`, `the`, and `of` have minimal attention in both methods.
4. **CoT Baseline**:
- CoT values are generally below 0.01, with occasional spikes (e.g., `between` ≈0.008).
5. **Repeated Tokens**:
- `$` and `%` appear twice, with similar patterns in both methods.
### Interpretation
The data suggests that the **Latent method** prioritizes numerical tokens (`120`, `130`, `%`) and question marks (`?`), potentially indicating stronger focus on quantitative or interrogative elements. The **CoT baseline** shows diffuse attention, with minimal intensity across all tokens. This divergence implies that Latent may better isolate critical tokens for tasks requiring precision, while CoT distributes attention more evenly but weakly. The repeated tokens (`$`, `%`, `of`) suggest context-dependent variations in attention, possibly reflecting syntactic or semantic roles in different prompt structures.