\n
## Diagram: Information Retrieval Process Flow
### Overview
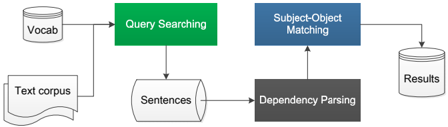
The image depicts a diagram illustrating a process flow for information retrieval. It shows how a query is processed through several stages, starting from a vocabulary and text corpus, and culminating in results. The diagram uses rectangular blocks to represent processing steps and cylindrical shapes to represent data stores. Arrows indicate the flow of information between these components.
### Components/Axes
The diagram consists of the following components:
* **Vocab:** A cylindrical data store labeled "Vocab".
* **Text corpus:** A rolled-up document representing a "Text corpus" data store.
* **Query Searching:** A rectangular block labeled "Query Searching".
* **Subject-Object Matching:** A rectangular block labeled "Subject-Object Matching".
* **Sentences:** A cylindrical data store labeled "Sentences".
* **Dependency Parsing:** A rectangular block labeled "Dependency Parsing".
* **Results:** A cylindrical data store labeled "Results".
Arrows connect these components, indicating the flow of data.
### Detailed Analysis or Content Details
The process flow can be described as follows:
1. The "Vocab" data store and the "Text corpus" data store feed into the "Query Searching" block.
2. "Query Searching" outputs to the "Subject-Object Matching" block.
3. The "Sentences" data store feeds into the "Dependency Parsing" block.
4. "Subject-Object Matching" and "Dependency Parsing" both feed into the "Results" data store.
There are no numerical values or scales present in the diagram. It is a conceptual representation of a process.
### Key Observations
The diagram highlights a pipeline architecture for information retrieval. The process involves searching a vocabulary and text corpus, identifying subject-object relationships, parsing dependencies, and ultimately generating results. The parallel input to "Results" suggests that both subject-object matching and dependency parsing contribute to the final output.
### Interpretation
This diagram illustrates a common approach to information retrieval, particularly in the context of knowledge graphs or semantic search. The "Vocab" likely represents a controlled vocabulary or ontology used to standardize terms. The "Text corpus" is the source of information. "Query Searching" identifies relevant text based on a user's query. "Subject-Object Matching" extracts relationships between entities in the text. "Dependency Parsing" analyzes the grammatical structure of sentences to understand the relationships between words. Finally, "Results" presents the retrieved information to the user.
The diagram suggests a system designed to understand the *meaning* of text, not just find keywords. The inclusion of "Dependency Parsing" indicates a focus on semantic analysis. The parallel paths to "Results" suggest that both relational information (subject-object) and grammatical structure contribute to the final output. This is a typical architecture for a system that aims to provide more than just keyword-based search results.