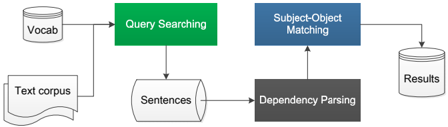
## Diagram: Natural Language Processing Pipeline for Subject-Object Extraction
### Overview
The image displays a technical flowchart illustrating a multi-stage pipeline for processing a text corpus to extract structured results, likely focusing on subject-object relationships. The diagram uses a combination of shapes (cylinders, rectangles, document icons) and directional arrows to denote data flow and processing steps.
### Components/Axes
The diagram consists of seven distinct components connected by arrows indicating the flow of data:
1. **Vocab** (Top-Left): Represented by a cylinder icon, indicating a data store or vocabulary resource.
2. **Text corpus** (Bottom-Left): Represented by a document icon, indicating the primary input text data.
3. **Query Searching** (Top-Center): A green rectangular process box.
4. **Sentences** (Center): A cylinder icon, indicating an intermediate data store.
5. **Dependency Parsing** (Bottom-Center): A dark gray rectangular process box.
6. **Subject-Object Matching** (Top-Right): A blue rectangular process box.
7. **Results** (Far-Right): A cylinder icon, indicating the final output data store.
### Detailed Analysis
The workflow proceeds as follows:
1. **Input Stage**: Two inputs feed into the first process:
* The **Vocab** cylinder (top-left) has an arrow pointing right to the **Query Searching** box.
* The **Text corpus** document (bottom-left) has an arrow pointing up to the **Query Searching** box.
2. **Query Searching Stage**: The green **Query Searching** process box receives inputs from both Vocab and Text corpus. It has a single output arrow pointing downward.
3. **Intermediate Storage**: The output from Query Searching flows into the **Sentences** cylinder (center). This suggests the query search step filters or retrieves relevant sentences from the corpus.
4. **Parsing Stage**: An arrow points from the **Sentences** cylinder to the right, into the **Dependency Parsing** process box (dark gray, bottom-center). This step likely analyzes the grammatical structure of each sentence.
5. **Matching Stage**: An arrow points upward from the **Dependency Parsing** box to the **Subject-Object Matching** process box (blue, top-right). This step presumably uses the parsed dependency trees to identify and match subjects with their corresponding objects.
6. **Output Stage**: A final arrow points from the **Subject-Object Matching** box to the right, into the **Results** cylinder. This is the terminal data store for the extracted information.
### Key Observations
* **Process Color Coding**: The three processing stages are distinctly colored: green for initial search, dark gray for parsing, and blue for final matching.
* **Data Flow Logic**: The pipeline follows a clear, linear sequence: Input -> Search -> Store Sentences -> Parse -> Match -> Store Results.
* **Component Semantics**: The use of cylinder icons for "Vocab," "Sentences," and "Results" consistently denotes data at rest, while rectangular boxes denote active processing steps.
* **Spatial Layout**: The diagram is organized with inputs on the left, processing in the center, and output on the right. The "Subject-Object Matching" and "Query Searching" processes are aligned at the top, while "Dependency Parsing" is positioned below them, creating a slight zig-zag flow.
### Interpretation
This diagram outlines a structured approach to information extraction from unstructured text. The pipeline's purpose is to transform a raw **Text corpus** into a structured set of **Results** containing subject-object relationships.
The process suggests a method where:
1. A vocabulary or query set (**Vocab**) is used to search the corpus for relevant sentences.
2. These sentences are isolated for further analysis.
3. **Dependency Parsing** is applied to understand the grammatical relationships within each sentence (e.g., identifying which noun is the subject and which is the object of a verb).
4. The **Subject-Object Matching** step then applies rules or models to the parsed data to formally pair subjects with their objects.
5. The final pairs are stored as structured output.
This type of pipeline is fundamental to tasks like building knowledge graphs, populating databases, or conducting semantic analysis, where the goal is to convert free-form text into queryable, relational data. The separation of "Query Searching" from "Subject-Object Matching" implies a two-stage filtering process: first to find relevant text passages, and second to extract specific relational facts from them.