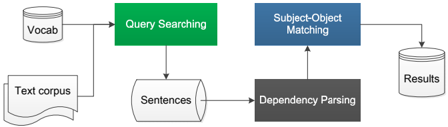
## Flowchart: Text Processing Pipeline
### Overview
The image depicts a multi-stage text processing pipeline with interconnected components. The flowchart uses color-coded blocks (green, blue, gray) to represent distinct processing stages, with arrows indicating data flow direction. Vocabulary and text corpus inputs feed into the system, culminating in structured results.
### Components/Axes
1. **Input Sources**:
- **Vocab**: Circular container (left side)
- **Text corpus**: Rectangular document icon (bottom-left)
2. **Processing Stages**:
- **Query Searching**: Green rectangle (central-left)
- **Sentences**: Cylinder container (below Query Searching)
- **Dependency Parsing**: Dark gray rectangle (center-right)
- **Subject-Object Matching**: Blue rectangle (top-right)
3. **Output**:
- **Results**: Cylinder container (far right)
4. **Color Legend**:
- Green: Query Searching
- Blue: Subject-Object Matching
- Gray: Dependency Parsing
### Detailed Analysis
1. **Flow Direction**:
- **Left to Right**: Primary data flow from inputs to outputs
- **Bottom to Top**: Secondary vertical flow from Sentences to Dependency Parsing
2. **Component Relationships**:
- **Vocab/Text corpus** → **Query Searching** (green)
- **Query Searching** → **Sentences** (cylinder)
- **Sentences** → **Dependency Parsing** (gray)
- **Dependency Parsing** → **Subject-Object Matching** (blue)
- **Subject-Object Matching** → **Results**
3. **Spatial Grounding**:
- Inputs clustered on the left
- Processing stages form a diagonal progression from bottom-left (green) to top-right (blue)
- Results container isolated on the far right
### Key Observations
1. **Modular Design**: Each processing stage operates as an independent module with clear input/output boundaries
2. **Color Coding**: Distinct colors prevent ambiguity between processing stages
3. **Bidirectional Flow**: While primary flow is left→right, the vertical connection between Sentences and Dependency Parsing creates a feedback loop
4. **Result Isolation**: Final output is physically separated from processing stages, emphasizing output purity
### Interpretation
This flowchart represents a natural language processing (NLP) pipeline where:
1. **Vocabulary and text corpus** serve as foundational inputs
2. **Query Searching** (green) acts as the initial filtering/extraction stage
3. **Dependency Parsing** (gray) introduces structural analysis of sentences
4. **Subject-Object Matching** (blue) represents the core relationship extraction component
5. The vertical connection between Sentences and Dependency Parsing suggests iterative refinement of linguistic analysis
6. The isolated Results container implies a final validation or formatting stage before output
The color-coded modular design emphasizes separation of concerns, while the bidirectional flow acknowledges the iterative nature of NLP processing. The system architecture prioritizes clear data provenance, with each stage building upon the previous while maintaining distinct functional responsibilities.