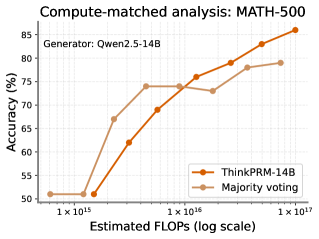
## Line Graph: Compute-matched analysis: MATH-500
### Overview
The image is a line graph comparing the accuracy of two computational models, **ThinkPRM-14B** and **Majority voting**, across varying computational costs (FLOPs) on the MATH-500 benchmark. The x-axis uses a logarithmic scale for FLOPs, while the y-axis represents accuracy in percentage.
### Components/Axes
- **X-axis**: "Estimated FLOPs (log scale)" with markers at `1×10¹⁵`, `1×10¹⁶`, and `1×10¹⁷`.
- **Y-axis**: "Accuracy (%)" ranging from 50% to 85% in 5% increments.
- **Legend**: Located at the bottom-right corner, with:
- **Orange line**: "ThinkPRM-14B"
- **Beige line**: "Majority voting"
- **Title**: "Compute-matched analysis: MATH-500" at the top.
- **Subtitle**: "Generator: Qwen2.5-14B" in the top-left corner.
### Detailed Analysis
#### ThinkPRM-14B (Orange Line)
- **Trend**: Steadily increases from ~50% at `1×10¹⁵` FLOPs to ~85% at `1×10¹⁷` FLOPs.
- **Key Data Points**:
- `1×10¹⁵` FLOPs: ~50% accuracy.
- `1×10¹⁶` FLOPs: ~70% accuracy.
- `1×10¹⁷` FLOPs: ~85% accuracy.
#### Majority Voting (Beige Line)
- **Trend**: Gradual increase from ~50% at `1×10¹⁵` FLOPs to ~78% at `1×10¹⁷` FLOPs.
- **Key Data Points**:
- `1×10¹⁵` FLOPs: ~50% accuracy.
- `1×10¹⁶` FLOPs: ~72% accuracy.
- `1×10¹⁷` FLOPs: ~78% accuracy.
### Key Observations
1. **Performance Gap**: ThinkPRM-14B consistently outperforms Majority voting across all FLOP levels, with the gap widening at higher computational costs.
2. **Scalability**: ThinkPRM-14B shows a steeper improvement curve, suggesting better utilization of increased computational resources.
3. **Majority Voting Plateau**: Majority voting’s accuracy plateaus near 78% despite further FLOP increases, indicating diminishing returns.
### Interpretation
The data demonstrates that **ThinkPRM-14B** achieves significantly higher accuracy than **Majority voting** as computational resources scale. This suggests that ThinkPRM-14B’s architecture or training is more effective at leveraging computational power for the MATH-500 task. Majority voting, while simpler, shows limited scalability, implying it may rely on heuristic aggregation rather than model-specific optimization. The results highlight the importance of model design in computational efficiency for complex reasoning tasks.