TECHNICAL ASSET FINGERPRINT
e84d2a1610e8d193c0c43fb0
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
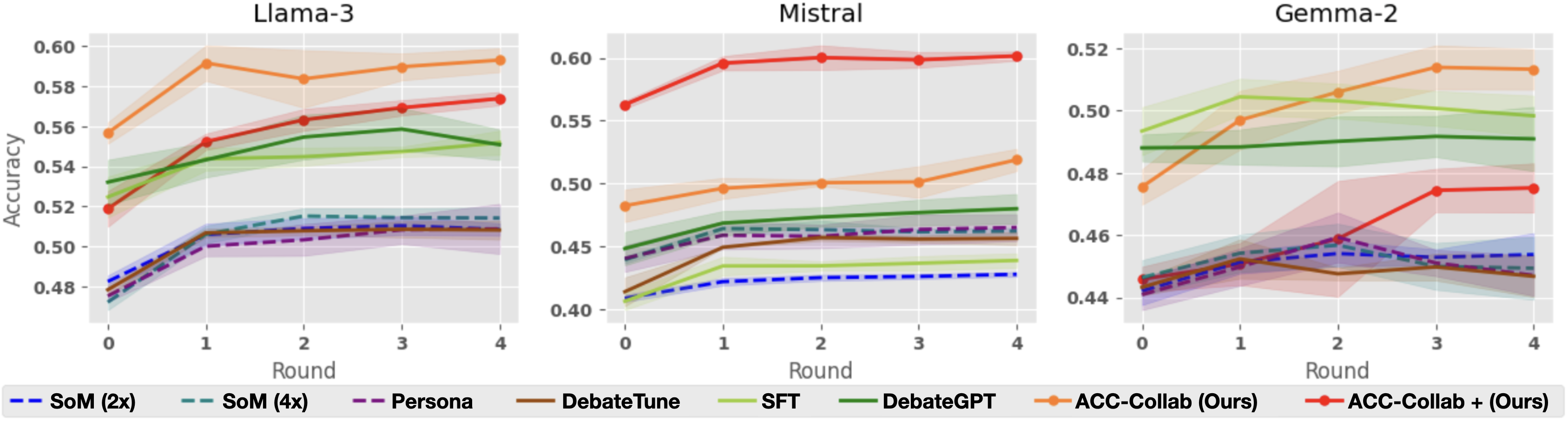
## Line Charts: Model Accuracy vs. Round
### Overview
The image presents three line charts comparing the accuracy of different models (Llama-3, Mistral, and Gemma-2) across several rounds of interaction or training. Each chart displays the performance of multiple methods, including "SoM (2x)", "SoM (4x)", "Persona", "DebateTune", "SFT", "DebateGPT", "ACC-Collab (Ours)", and "ACC-Collab + (Ours)". The x-axis represents the round number (0 to 4), and the y-axis represents the accuracy score. Shaded regions around each line indicate the uncertainty or variance in the accuracy.
### Components/Axes
* **Titles:**
* Top-left chart: "Llama-3"
* Top-middle chart: "Mistral"
* Top-right chart: "Gemma-2"
* **X-axis:** "Round", with markers at 0, 1, 2, 3, and 4.
* **Y-axis:** "Accuracy", ranging from 0.48 to 0.60 for Llama-3, 0.40 to 0.60 for Mistral, and 0.44 to 0.52 for Gemma-2.
* **Legend:** Located at the bottom of the image, associating line colors and styles with specific methods:
* Blue dashed line: "SoM (2x)"
* Teal dashed line: "SoM (4x)"
* Purple dashed line: "Persona"
* Brown solid line: "DebateTune"
* Light green solid line: "SFT"
* Dark green solid line: "DebateGPT"
* Orange solid line: "ACC-Collab (Ours)"
* Red solid line: "ACC-Collab + (Ours)"
### Detailed Analysis
#### Llama-3 Chart
* **SoM (2x)** (Blue dashed): Starts at approximately 0.48 and increases to around 0.51, then remains relatively stable.
* **SoM (4x)** (Teal dashed): Similar to SoM (2x), starting around 0.48 and increasing to approximately 0.51, then stabilizing.
* **Persona** (Purple dashed): Starts around 0.48 and increases to approximately 0.50, then stabilizes.
* **DebateTune** (Brown solid): Starts around 0.48 and increases to approximately 0.51, then stabilizes.
* **SFT** (Light green solid): Starts around 0.52 and increases to approximately 0.56.
* **DebateGPT** (Dark green solid): Starts around 0.53 and increases to approximately 0.55.
* **ACC-Collab (Ours)** (Orange solid): Starts around 0.56, increases to approximately 0.59 at round 1, then decreases slightly to approximately 0.58 by round 4.
* **ACC-Collab + (Ours)** (Red solid): Starts around 0.52, increases to approximately 0.57 by round 4.
#### Mistral Chart
* **SoM (2x)** (Blue dashed): Starts around 0.40 and increases to approximately 0.43, then remains relatively stable.
* **SoM (4x)** (Teal dashed): Starts around 0.45 and increases slightly to approximately 0.47, then stabilizes.
* **Persona** (Purple dashed): Starts around 0.45 and increases slightly to approximately 0.47, then stabilizes.
* **DebateTune** (Brown solid): Starts around 0.42 and increases to approximately 0.46, then stabilizes.
* **SFT** (Light green solid): Starts around 0.44 and increases slightly to approximately 0.46, then stabilizes.
* **DebateGPT** (Dark green solid): Starts around 0.45 and increases slightly to approximately 0.48, then stabilizes.
* **ACC-Collab (Ours)** (Orange solid): Starts around 0.48, increases to approximately 0.50 by round 1, then remains relatively stable.
* **ACC-Collab + (Ours)** (Red solid): Starts around 0.57, increases to approximately 0.60 by round 1, then remains relatively stable.
#### Gemma-2 Chart
* **SoM (2x)** (Blue dashed): Starts around 0.44 and increases to approximately 0.46, then remains relatively stable.
* **SoM (4x)** (Teal dashed): Starts around 0.48 and increases slightly to approximately 0.51, then stabilizes.
* **Persona** (Purple dashed): Starts around 0.44 and increases slightly to approximately 0.46, then stabilizes.
* **DebateTune** (Brown solid): Starts around 0.44 and increases slightly to approximately 0.45, then stabilizes.
* **SFT** (Light green solid): Starts around 0.48 and increases slightly to approximately 0.49, then stabilizes.
* **DebateGPT** (Dark green solid): Starts around 0.49 and increases slightly to approximately 0.50, then stabilizes.
* **ACC-Collab (Ours)** (Orange solid): Starts around 0.48, increases to approximately 0.52 by round 4.
* **ACC-Collab + (Ours)** (Red solid): Starts around 0.45, increases to approximately 0.48 by round 3, then decreases slightly to approximately 0.47 by round 4.
### Key Observations
* **ACC-Collab + (Ours)** generally performs well across all models, often achieving the highest accuracy or a close second.
* **ACC-Collab (Ours)** also shows strong performance, particularly in the Llama-3 and Gemma-2 models.
* **SoM (2x), SoM (4x), Persona, and DebateTune** tend to have lower and more stable accuracy scores compared to the other methods.
* The accuracy improvements tend to occur in the initial rounds (0-1), with diminishing returns in later rounds.
* The shaded regions indicate varying degrees of uncertainty in the accuracy, with some methods showing more consistent performance than others.
### Interpretation
The charts suggest that "ACC-Collab + (Ours)" and "ACC-Collab (Ours)" are effective methods for improving model accuracy across different language models (Llama-3, Mistral, and Gemma-2). The relatively flat performance of "SoM (2x)", "SoM (4x)", "Persona", and "DebateTune" indicates that these methods may not be as effective in this context. The initial rounds of interaction or training appear to be the most crucial for achieving accuracy gains. The uncertainty regions highlight the variability in performance, which could be due to factors such as data sampling or model initialization. The data demonstrates the relative effectiveness of different training or fine-tuning approaches for language models.
DECODING INTELLIGENCE...
EXPERT: nemotron-free VERSION 1
RUNTIME: free/nvidia/nemotron-nano-12b-v2-vl:free
INTEL_VERIFIED
## Line Graphs: Model Performance Across Rounds (Llama-3, Mistral, Gemma-2)
### Overview
The image contains three line graphs comparing the accuracy of different AI models across four rounds of evaluation. Each graph represents a different base model (Llama-3, Mistral, Gemma-2), with multiple data series showing performance trends for various training methodologies. The graphs use colored lines with shaded confidence intervals to represent model accuracy over time.
### Components/Axes
- **X-axis**: "Round" (0 to 4), representing evaluation rounds
- **Y-axis**: "Accuracy" (0.40 to 0.60), measured as a decimal
- **Legends**: Located at the bottom of each graph, mapping colors to models:
- Blue dashed: SoM (2x)
- Teal dashed: SoM (4x)
- Purple dashed: Persona
- Brown solid: DebateTune
- Green solid: SFT
- Dark green solid: DebateGPT
- Orange solid: ACC-Collab (Ours)
- Red solid: ACC-Collab + (Ours)
### Detailed Analysis
#### Llama-3 Graph
- **Orange line (ACC-Collab (Ours))**: Starts at 0.56 (Round 0), peaks at 0.59 (Round 4)
- **Green line (DebateGPT)**: Starts at 0.52 (Round 0), peaks at 0.56 (Round 2), then declines to 0.55 (Round 4)
- **Blue dashed (SoM 2x)**: Starts at 0.48 (Round 0), rises to 0.51 (Round 2), then plateaus
- **Teal dashed (SoM 4x)**: Starts at 0.47 (Round 0), rises to 0.51 (Round 2), then declines to 0.50 (Round 4)
- **Purple dashed (Persona)**: Starts at 0.49 (Round 0), rises to 0.51 (Round 2), then declines to 0.50 (Round 4)
- **Brown solid (DebateTune)**: Starts at 0.49 (Round 0), rises to 0.51 (Round 2), then declines to 0.50 (Round 4)
- **Green solid (SFT)**: Starts at 0.52 (Round 0), rises to 0.55 (Round 2), then declines to 0.54 (Round 4)
#### Mistral Graph
- **Red line (ACC-Collab + (Ours))**: Starts at 0.55 (Round 0), rises to 0.60 (Round 1), plateaus at 0.59-0.60
- **Orange line (ACC-Collab (Ours))**: Starts at 0.49 (Round 0), rises to 0.50 (Round 1), plateaus at 0.50-0.51
- **Blue dashed (SoM 2x)**: Starts at 0.40 (Round 0), rises to 0.43 (Round 4)
- **Teal dashed (SoM 4x)**: Starts at 0.45 (Round 0), rises to 0.47 (Round 1), plateaus at 0.47-0.48
- **Purple dashed (Persona)**: Starts at 0.44 (Round 0), rises to 0.47 (Round 1), plateaus at 0.47-0.48
- **Brown solid (DebateTune)**: Starts at 0.43 (Round 0), rises to 0.46 (Round 1), plateaus at 0.46-0.47
- **Green solid (SFT)**: Starts at 0.42 (Round 0), rises to 0.45 (Round 1), plateaus at 0.45-0.46
- **Dark green solid (DebateGPT)**: Starts at 0.45 (Round 0), rises to 0.48 (Round 1), plateaus at 0.48-0.49
#### Gemma-2 Graph
- **Orange line (ACC-Collab (Ours))**: Starts at 0.48 (Round 0), rises to 0.51 (Round 4)
- **Red line (ACC-Collab + (Ours))**: Starts at 0.44 (Round 0), rises to 0.49 (Round 4)
- **Blue dashed (SoM 2x)**: Starts at 0.44 (Round 0), rises to 0.46 (Round 2), plateaus at 0.46-0.47
- **Teal dashed (SoM 4x)**: Starts at 0.45 (Round 0), rises to 0.47 (Round 2), plateaus at 0.47-0.48
- **Purple dashed (Persona)**: Starts at 0.44 (Round 0), rises to 0.47 (Round 2), plateaus at 0.47-0.48
- **Brown solid (DebateTune)**: Starts at 0.43 (Round 0), rises to 0.46 (Round 2), plateaus at 0.46-0.47
- **Green solid (SFT)**: Starts at 0.47 (Round 0), rises to 0.50 (Round 2), plateaus at 0.50-0.51
- **Dark green solid (DebateGPT)**: Starts at 0.48 (Round 0), rises to 0.49 (Round 2), plateaus at 0.49-0.50
### Key Observations
1. **ACC-Collab Methods**: Consistently outperform other models across all three base models, with ACC-Collab + (Ours) showing the highest accuracy gains
2. **SoM Models**: Show improvement in early rounds but plateau or decline in later rounds, with 4x versions generally outperforming 2x
3. **DebateGPT**: Shows strong performance in Mistral but underperforms in Llama-3 and Gemma-2 compared to ACC-Collab methods
4. **SFT**: Shows moderate improvement across all models but lags behind ACC-Collab methods
5. **Confidence Intervals**: Shaded areas indicate variability, with ACC-Collab methods showing narrower intervals suggesting more consistent performance
### Interpretation
The data demonstrates that the ACC-Collab methodology (both base and enhanced versions) consistently delivers superior performance across all evaluated models, particularly in later rounds. This suggests that collaborative training approaches may be more effective than individual model training strategies. The SoM models show diminishing returns with increased complexity (4x vs 2x), while DebateGPT's performance varies significantly between base models. The shaded confidence intervals indicate that ACC-Collab methods have more reliable performance, with less variance between rounds. These findings imply that collaborative training frameworks could be prioritized for developing more robust AI systems, particularly when dealing with complex tasks requiring sustained performance across multiple evaluation rounds.
DECODING INTELLIGENCE...