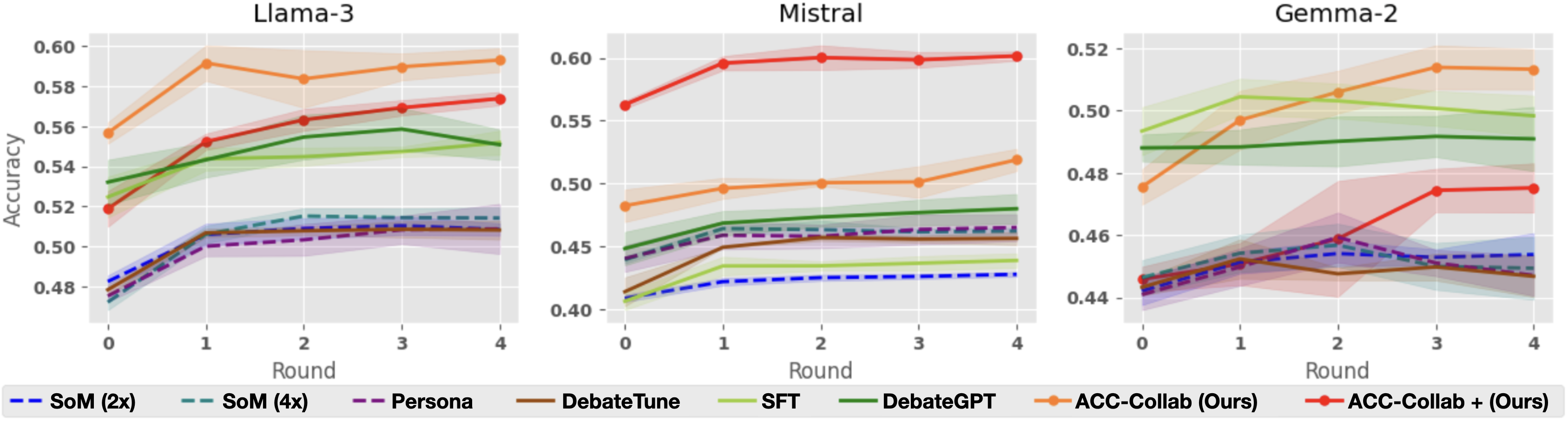
## Line Charts: Model Accuracy vs. Round
### Overview
The image presents three line charts comparing the accuracy of different models (Llama-3, Mistral, and Gemma-2) across several rounds of interaction or training. Each chart displays the performance of multiple methods, including "SoM (2x)", "SoM (4x)", "Persona", "DebateTune", "SFT", "DebateGPT", "ACC-Collab (Ours)", and "ACC-Collab + (Ours)". The x-axis represents the round number (0 to 4), and the y-axis represents the accuracy score. Shaded regions around each line indicate the uncertainty or variance in the accuracy.
### Components/Axes
* **Titles:**
* Top-left chart: "Llama-3"
* Top-middle chart: "Mistral"
* Top-right chart: "Gemma-2"
* **X-axis:** "Round", with markers at 0, 1, 2, 3, and 4.
* **Y-axis:** "Accuracy", ranging from 0.48 to 0.60 for Llama-3, 0.40 to 0.60 for Mistral, and 0.44 to 0.52 for Gemma-2.
* **Legend:** Located at the bottom of the image, associating line colors and styles with specific methods:
* Blue dashed line: "SoM (2x)"
* Teal dashed line: "SoM (4x)"
* Purple dashed line: "Persona"
* Brown solid line: "DebateTune"
* Light green solid line: "SFT"
* Dark green solid line: "DebateGPT"
* Orange solid line: "ACC-Collab (Ours)"
* Red solid line: "ACC-Collab + (Ours)"
### Detailed Analysis
#### Llama-3 Chart
* **SoM (2x)** (Blue dashed): Starts at approximately 0.48 and increases to around 0.51, then remains relatively stable.
* **SoM (4x)** (Teal dashed): Similar to SoM (2x), starting around 0.48 and increasing to approximately 0.51, then stabilizing.
* **Persona** (Purple dashed): Starts around 0.48 and increases to approximately 0.50, then stabilizes.
* **DebateTune** (Brown solid): Starts around 0.48 and increases to approximately 0.51, then stabilizes.
* **SFT** (Light green solid): Starts around 0.52 and increases to approximately 0.56.
* **DebateGPT** (Dark green solid): Starts around 0.53 and increases to approximately 0.55.
* **ACC-Collab (Ours)** (Orange solid): Starts around 0.56, increases to approximately 0.59 at round 1, then decreases slightly to approximately 0.58 by round 4.
* **ACC-Collab + (Ours)** (Red solid): Starts around 0.52, increases to approximately 0.57 by round 4.
#### Mistral Chart
* **SoM (2x)** (Blue dashed): Starts around 0.40 and increases to approximately 0.43, then remains relatively stable.
* **SoM (4x)** (Teal dashed): Starts around 0.45 and increases slightly to approximately 0.47, then stabilizes.
* **Persona** (Purple dashed): Starts around 0.45 and increases slightly to approximately 0.47, then stabilizes.
* **DebateTune** (Brown solid): Starts around 0.42 and increases to approximately 0.46, then stabilizes.
* **SFT** (Light green solid): Starts around 0.44 and increases slightly to approximately 0.46, then stabilizes.
* **DebateGPT** (Dark green solid): Starts around 0.45 and increases slightly to approximately 0.48, then stabilizes.
* **ACC-Collab (Ours)** (Orange solid): Starts around 0.48, increases to approximately 0.50 by round 1, then remains relatively stable.
* **ACC-Collab + (Ours)** (Red solid): Starts around 0.57, increases to approximately 0.60 by round 1, then remains relatively stable.
#### Gemma-2 Chart
* **SoM (2x)** (Blue dashed): Starts around 0.44 and increases to approximately 0.46, then remains relatively stable.
* **SoM (4x)** (Teal dashed): Starts around 0.48 and increases slightly to approximately 0.51, then stabilizes.
* **Persona** (Purple dashed): Starts around 0.44 and increases slightly to approximately 0.46, then stabilizes.
* **DebateTune** (Brown solid): Starts around 0.44 and increases slightly to approximately 0.45, then stabilizes.
* **SFT** (Light green solid): Starts around 0.48 and increases slightly to approximately 0.49, then stabilizes.
* **DebateGPT** (Dark green solid): Starts around 0.49 and increases slightly to approximately 0.50, then stabilizes.
* **ACC-Collab (Ours)** (Orange solid): Starts around 0.48, increases to approximately 0.52 by round 4.
* **ACC-Collab + (Ours)** (Red solid): Starts around 0.45, increases to approximately 0.48 by round 3, then decreases slightly to approximately 0.47 by round 4.
### Key Observations
* **ACC-Collab + (Ours)** generally performs well across all models, often achieving the highest accuracy or a close second.
* **ACC-Collab (Ours)** also shows strong performance, particularly in the Llama-3 and Gemma-2 models.
* **SoM (2x), SoM (4x), Persona, and DebateTune** tend to have lower and more stable accuracy scores compared to the other methods.
* The accuracy improvements tend to occur in the initial rounds (0-1), with diminishing returns in later rounds.
* The shaded regions indicate varying degrees of uncertainty in the accuracy, with some methods showing more consistent performance than others.
### Interpretation
The charts suggest that "ACC-Collab + (Ours)" and "ACC-Collab (Ours)" are effective methods for improving model accuracy across different language models (Llama-3, Mistral, and Gemma-2). The relatively flat performance of "SoM (2x)", "SoM (4x)", "Persona", and "DebateTune" indicates that these methods may not be as effective in this context. The initial rounds of interaction or training appear to be the most crucial for achieving accuracy gains. The uncertainty regions highlight the variability in performance, which could be due to factors such as data sampling or model initialization. The data demonstrates the relative effectiveness of different training or fine-tuning approaches for language models.