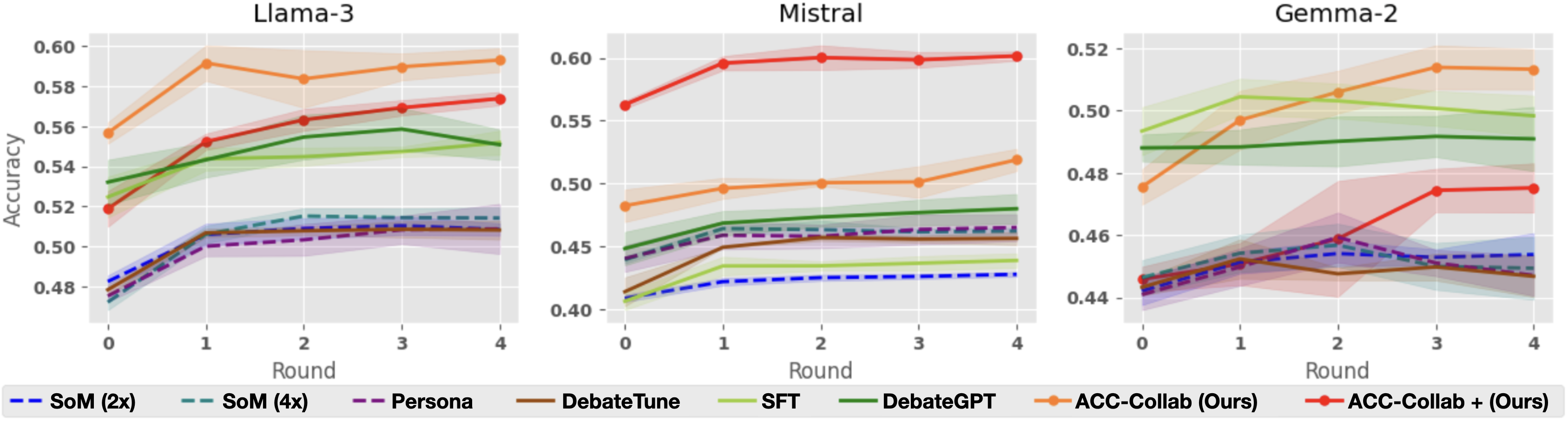
## Line Charts: Performance of Various Methods Across Three AI Models
### Overview
The image displays three side-by-side line charts, each tracking the "Accuracy" (y-axis) of eight different methods over five sequential "Rounds" (x-axis, 0-4). The charts are titled by the base AI model being evaluated: "Llama-3", "Mistral", and "Gemma-2". A shared legend at the bottom identifies the eight methods, which are distinguished by line color and style (solid or dashed). Each data series includes a shaded region, likely representing confidence intervals or standard deviation.
### Components/Axes
* **Titles:** Three individual chart titles: "Llama-3" (left), "Mistral" (center), "Gemma-2" (right).
* **Y-Axis:** Labeled "Accuracy". The scale varies per chart:
* Llama-3: 0.48 to 0.60 (increments of 0.02).
* Mistral: 0.40 to 0.60 (increments of 0.05).
* Gemma-2: 0.44 to 0.52 (increments of 0.02).
* **X-Axis:** Labeled "Round" for all three charts, with markers at 0, 1, 2, 3, and 4.
* **Legend:** Located at the bottom of the entire figure, spanning its width. It defines the following eight methods:
1. `SoM (2x)`: Blue dashed line.
2. `SoM (4x)`: Teal dashed line.
3. `Persona`: Purple dashed line.
4. `DebateTune`: Brown solid line.
5. `SFT`: Light green solid line.
6. `DebateGPT`: Dark green solid line.
7. `ACC-Collab (Ours)`: Orange solid line with circular markers.
8. `ACC-Collab + (Ours)`: Red solid line with circular markers.
### Detailed Analysis
**Chart 1: Llama-3**
* **Trend Verification & Data Points:**
* `ACC-Collab (Ours)` (Orange): Starts highest at ~0.555 (Round 0), peaks at ~0.592 (Round 1), then stabilizes around 0.585-0.592. It is the top-performing method throughout.
* `ACC-Collab + (Ours)` (Red): Starts at ~0.518, shows a steady upward trend to ~0.573 by Round 4, becoming the second-highest.
* `DebateGPT` (Dark Green): Starts at ~0.532, rises to ~0.558 (Round 3), then dips slightly to ~0.551 (Round 4).
* `SFT` (Light Green): Starts at ~0.525, rises gently to ~0.548 (Round 3), then dips to ~0.540.
* The four dashed-line methods (`SoM (2x)`, `SoM (4x)`, `Persona`, `DebateTune`) cluster tightly between ~0.475 and ~0.515. They all show a sharp initial increase from Round 0 to 1, then plateau. `SoM (4x)` (Teal) appears marginally highest within this cluster by Round 4 (~0.515).
**Chart 2: Mistral**
* **Trend Verification & Data Points:**
* `ACC-Collab + (Ours)` (Red): Dominates this chart. Starts at ~0.562, jumps to ~0.598 (Round 1), and remains flat at ~0.600 through Round 4.
* `ACC-Collab (Ours)` (Orange): Starts at ~0.482, rises steadily to ~0.518 (Round 4). It is clearly separated below the red line but above all others.
* `DebateGPT` (Dark Green): Starts at ~0.448, rises to ~0.478 (Round 4).
* `SFT` (Light Green): Starts lowest at ~0.405, rises to ~0.438 (Round 4).
* The dashed-line cluster (`SoM (2x)`, `SoM (4x)`, `Persona`, `DebateTune`) is again tightly grouped, starting between ~0.410-0.440 and ending between ~0.455-0.465. `DebateTune` (Brown) is at the bottom of this cluster.
**Chart 3: Gemma-2**
* **Trend Verification & Data Points:**
* `ACC-Collab (Ours)` (Orange): Starts at ~0.476, shows a strong upward trend to peak at ~0.515 (Round 3), then dips slightly to ~0.513. It is the top performer from Round 2 onward.
* `SFT` (Light Green): Starts highest at ~0.493, peaks at ~0.505 (Round 1), then declines to ~0.498 (Round 4).
* `DebateGPT` (Dark Green): Starts at ~0.488, remains very flat, ending at ~0.490.
* `ACC-Collab + (Ours)` (Red): Starts low at ~0.445, shows a late surge from Round 2 (~0.458) to Round 3 (~0.475), ending at ~0.476.
* The dashed-line cluster (`SoM (2x)`, `SoM (4x)`, `Persona`, `DebateTune`) starts between ~0.440-0.448. They show modest gains, ending between ~0.448-0.455. `DebateTune` (Brown) shows a notable dip at Round 2 before recovering.
### Key Observations
1. **Model-Dependent Performance:** The relative effectiveness of the methods varies significantly by base model. `ACC-Collab + (Ours)` is dominant on Mistral, competitive on Llama-3, but underperforms on Gemma-2 until later rounds. `ACC-Collab (Ours)` is consistently strong, leading on Llama-3 and Gemma-2.
2. **Clustering of Baselines:** The four methods represented by dashed lines (`SoM (2x)`, `SoM (4x)`, `Persona`, `DebateTune`) consistently form a low-performing cluster with very similar trajectories across all three models.
3. **Round 0 to 1 Jump:** Nearly all methods show their most significant accuracy gain between Round 0 and Round 1, after which improvements become more gradual or plateau.
4. **Uncertainty Bands:** The shaded confidence intervals are notably wider for the `ACC-Collab` variants (orange and red lines), suggesting higher variance in their performance compared to the more tightly banded baseline methods.
### Interpretation
The data suggests that the proposed methods, **ACC-Collab (Ours)** and its variant **ACC-Collab + (Ours)**, generally outperform the baseline techniques (SoM, Persona, DebateTune, SFT, DebateGPT) in multi-round accuracy evaluation across different large language models. The "Ours" label indicates these are the novel contributions of the paper or work from which this figure is taken.
The performance hierarchy is not absolute but is **model-sensitive**. This implies that the optimal collaborative or debate strategy may depend on the underlying capabilities or biases of the base model (Llama-3 vs. Mistral vs. Gemma-2). The consistent underperformance and clustering of the dashed-line methods suggest they represent a similar class of simpler or less effective approaches.
The significant improvement from Round 0 to Round 1 across the board indicates that even a single round of interaction or refinement provides substantial benefit over the base model's initial output. The plateauing effect suggests diminishing returns with additional rounds for most methods. The wider variance for the ACC-Collab methods might be a trade-off for their higher peak performance, indicating they are potentially more sensitive to initial conditions or input variations.