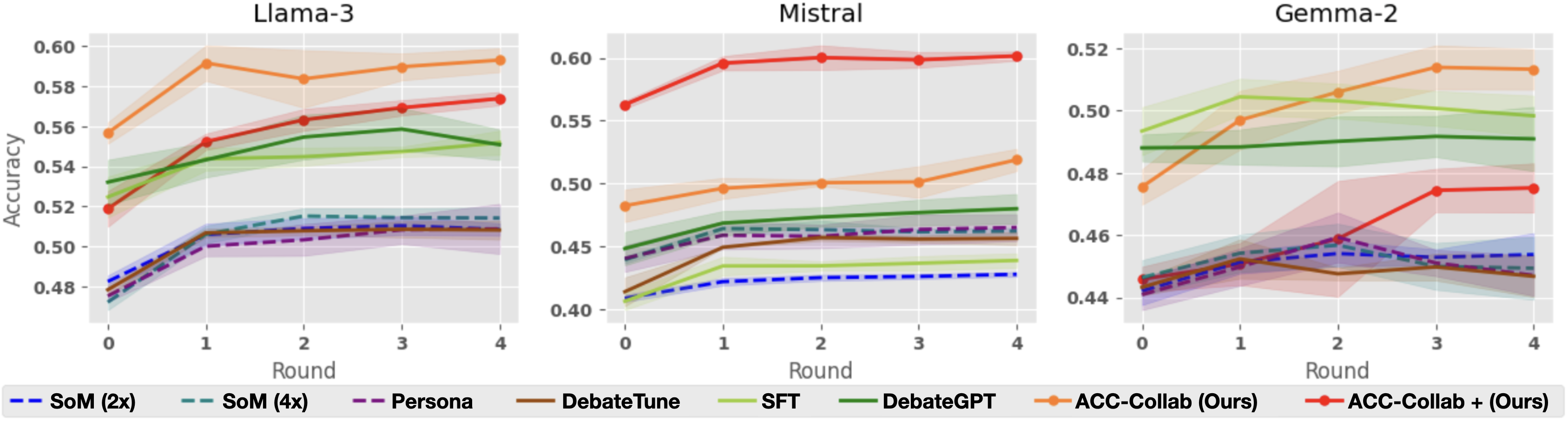
## Line Graphs: Model Performance Across Rounds (Llama-3, Mistral, Gemma-2)
### Overview
The image contains three line graphs comparing the accuracy of different AI models across four rounds of evaluation. Each graph represents a different base model (Llama-3, Mistral, Gemma-2), with multiple data series showing performance trends for various training methodologies. The graphs use colored lines with shaded confidence intervals to represent model accuracy over time.
### Components/Axes
- **X-axis**: "Round" (0 to 4), representing evaluation rounds
- **Y-axis**: "Accuracy" (0.40 to 0.60), measured as a decimal
- **Legends**: Located at the bottom of each graph, mapping colors to models:
- Blue dashed: SoM (2x)
- Teal dashed: SoM (4x)
- Purple dashed: Persona
- Brown solid: DebateTune
- Green solid: SFT
- Dark green solid: DebateGPT
- Orange solid: ACC-Collab (Ours)
- Red solid: ACC-Collab + (Ours)
### Detailed Analysis
#### Llama-3 Graph
- **Orange line (ACC-Collab (Ours))**: Starts at 0.56 (Round 0), peaks at 0.59 (Round 4)
- **Green line (DebateGPT)**: Starts at 0.52 (Round 0), peaks at 0.56 (Round 2), then declines to 0.55 (Round 4)
- **Blue dashed (SoM 2x)**: Starts at 0.48 (Round 0), rises to 0.51 (Round 2), then plateaus
- **Teal dashed (SoM 4x)**: Starts at 0.47 (Round 0), rises to 0.51 (Round 2), then declines to 0.50 (Round 4)
- **Purple dashed (Persona)**: Starts at 0.49 (Round 0), rises to 0.51 (Round 2), then declines to 0.50 (Round 4)
- **Brown solid (DebateTune)**: Starts at 0.49 (Round 0), rises to 0.51 (Round 2), then declines to 0.50 (Round 4)
- **Green solid (SFT)**: Starts at 0.52 (Round 0), rises to 0.55 (Round 2), then declines to 0.54 (Round 4)
#### Mistral Graph
- **Red line (ACC-Collab + (Ours))**: Starts at 0.55 (Round 0), rises to 0.60 (Round 1), plateaus at 0.59-0.60
- **Orange line (ACC-Collab (Ours))**: Starts at 0.49 (Round 0), rises to 0.50 (Round 1), plateaus at 0.50-0.51
- **Blue dashed (SoM 2x)**: Starts at 0.40 (Round 0), rises to 0.43 (Round 4)
- **Teal dashed (SoM 4x)**: Starts at 0.45 (Round 0), rises to 0.47 (Round 1), plateaus at 0.47-0.48
- **Purple dashed (Persona)**: Starts at 0.44 (Round 0), rises to 0.47 (Round 1), plateaus at 0.47-0.48
- **Brown solid (DebateTune)**: Starts at 0.43 (Round 0), rises to 0.46 (Round 1), plateaus at 0.46-0.47
- **Green solid (SFT)**: Starts at 0.42 (Round 0), rises to 0.45 (Round 1), plateaus at 0.45-0.46
- **Dark green solid (DebateGPT)**: Starts at 0.45 (Round 0), rises to 0.48 (Round 1), plateaus at 0.48-0.49
#### Gemma-2 Graph
- **Orange line (ACC-Collab (Ours))**: Starts at 0.48 (Round 0), rises to 0.51 (Round 4)
- **Red line (ACC-Collab + (Ours))**: Starts at 0.44 (Round 0), rises to 0.49 (Round 4)
- **Blue dashed (SoM 2x)**: Starts at 0.44 (Round 0), rises to 0.46 (Round 2), plateaus at 0.46-0.47
- **Teal dashed (SoM 4x)**: Starts at 0.45 (Round 0), rises to 0.47 (Round 2), plateaus at 0.47-0.48
- **Purple dashed (Persona)**: Starts at 0.44 (Round 0), rises to 0.47 (Round 2), plateaus at 0.47-0.48
- **Brown solid (DebateTune)**: Starts at 0.43 (Round 0), rises to 0.46 (Round 2), plateaus at 0.46-0.47
- **Green solid (SFT)**: Starts at 0.47 (Round 0), rises to 0.50 (Round 2), plateaus at 0.50-0.51
- **Dark green solid (DebateGPT)**: Starts at 0.48 (Round 0), rises to 0.49 (Round 2), plateaus at 0.49-0.50
### Key Observations
1. **ACC-Collab Methods**: Consistently outperform other models across all three base models, with ACC-Collab + (Ours) showing the highest accuracy gains
2. **SoM Models**: Show improvement in early rounds but plateau or decline in later rounds, with 4x versions generally outperforming 2x
3. **DebateGPT**: Shows strong performance in Mistral but underperforms in Llama-3 and Gemma-2 compared to ACC-Collab methods
4. **SFT**: Shows moderate improvement across all models but lags behind ACC-Collab methods
5. **Confidence Intervals**: Shaded areas indicate variability, with ACC-Collab methods showing narrower intervals suggesting more consistent performance
### Interpretation
The data demonstrates that the ACC-Collab methodology (both base and enhanced versions) consistently delivers superior performance across all evaluated models, particularly in later rounds. This suggests that collaborative training approaches may be more effective than individual model training strategies. The SoM models show diminishing returns with increased complexity (4x vs 2x), while DebateGPT's performance varies significantly between base models. The shaded confidence intervals indicate that ACC-Collab methods have more reliable performance, with less variance between rounds. These findings imply that collaborative training frameworks could be prioritized for developing more robust AI systems, particularly when dealing with complex tasks requiring sustained performance across multiple evaluation rounds.