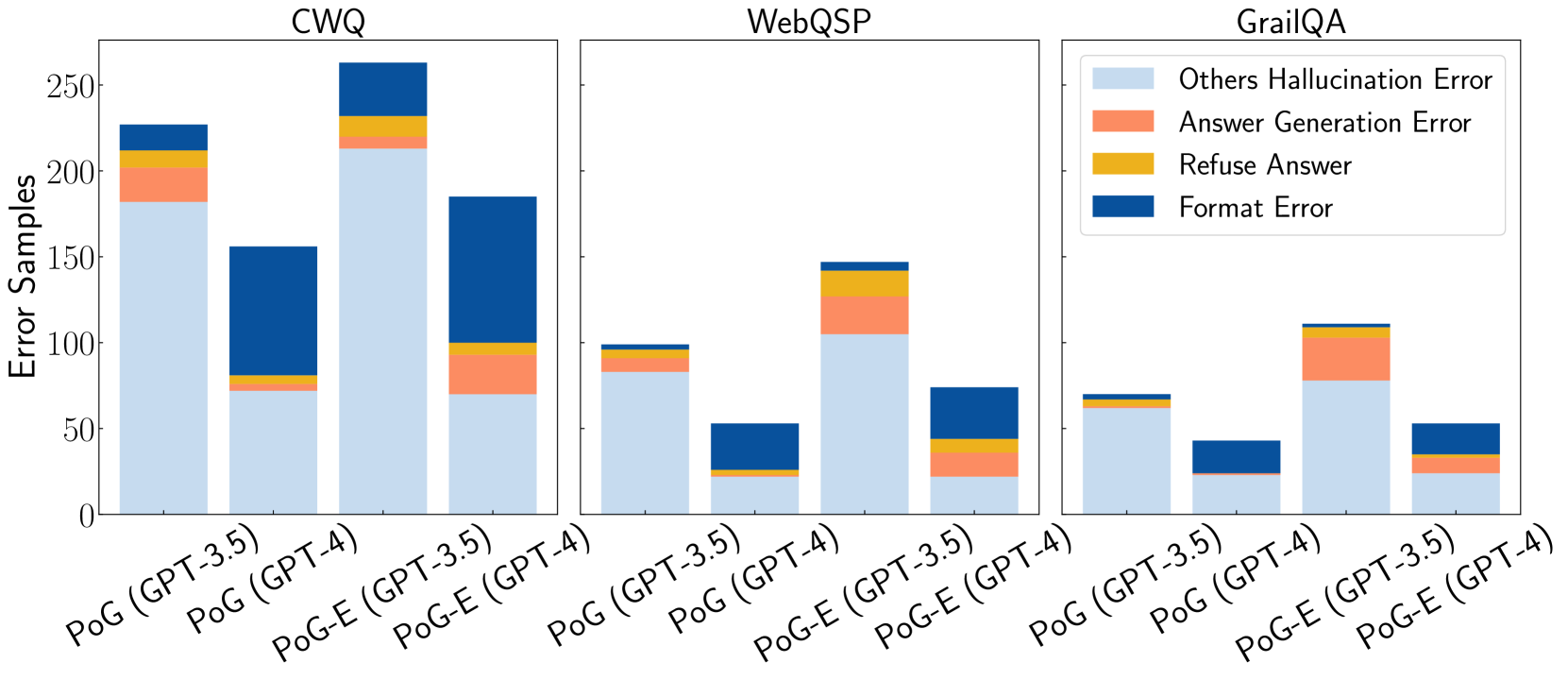
## Stacked Bar Chart: Error Analysis of Language Models
### Overview
The image presents a stacked bar chart comparing the error profiles of different language models (GPT-3.5 and GPT-4) under two prompting strategies (PoG and PoG-E) across three question answering datasets (CWQ, WebQSP, and GrailQA). The chart breaks down the errors into four categories: Others Hallucination Error, Answer Generation Error, Refuse Answer, and Format Error.
### Components/Axes
* **Title:** Error Samples
* **Y-axis:**
* Label: Error Samples
* Scale: 0 to 250, with tick marks at 0, 50, 100, 150, 200, and 250.
* **X-axis:**
* Categories: CWQ, WebQSP, GrailQA
* Sub-categories (within each category):
* PoG (GPT-3.5)
* PoG (GPT-4)
* PoG-E (GPT-3.5)
* PoG-E (GPT-4)
* **Legend (top-right):**
* Others Hallucination Error (light blue)
* Answer Generation Error (coral)
* Refuse Answer (gold)
* Format Error (dark blue)
### Detailed Analysis
**CWQ Dataset:**
* **PoG (GPT-3.5):**
* Others Hallucination Error: ~180
* Answer Generation Error: ~30
* Refuse Answer: ~10
* Format Error: ~10
* **PoG (GPT-4):**
* Others Hallucination Error: ~70
* Answer Generation Error: ~0
* Refuse Answer: ~10
* Format Error: ~70
* **PoG-E (GPT-3.5):**
* Others Hallucination Error: ~210
* Answer Generation Error: ~20
* Refuse Answer: ~10
* Format Error: ~20
* **PoG-E (GPT-4):**
* Others Hallucination Error: ~70
* Answer Generation Error: ~0
* Refuse Answer: ~30
* Format Error: ~90
**WebQSP Dataset:**
* **PoG (GPT-3.5):**
* Others Hallucination Error: ~80
* Answer Generation Error: ~0
* Refuse Answer: ~10
* Format Error: ~10
* **PoG (GPT-4):**
* Others Hallucination Error: ~20
* Answer Generation Error: ~0
* Refuse Answer: ~0
* Format Error: ~30
* **PoG-E (GPT-3.5):**
* Others Hallucination Error: ~110
* Answer Generation Error: ~30
* Refuse Answer: ~10
* Format Error: ~0
* **PoG-E (GPT-4):**
* Others Hallucination Error: ~70
* Answer Generation Error: ~0
* Refuse Answer: ~10
* Format Error: ~0
**GrailQA Dataset:**
* **PoG (GPT-3.5):**
* Others Hallucination Error: ~60
* Answer Generation Error: ~0
* Refuse Answer: ~5
* Format Error: ~5
* **PoG (GPT-4):**
* Others Hallucination Error: ~20
* Answer Generation Error: ~0
* Refuse Answer: ~0
* Format Error: ~25
* **PoG-E (GPT-3.5):**
* Others Hallucination Error: ~80
* Answer Generation Error: ~20
* Refuse Answer: ~10
* Format Error: ~0
* **PoG-E (GPT-4):**
* Others Hallucination Error: ~25
* Answer Generation Error: ~5
* Refuse Answer: ~0
* Format Error: ~20
### Key Observations
* **Hallucination Errors:** "Others Hallucination Error" is generally the most prevalent error type across all datasets and model configurations, indicated by the height of the light blue section.
* **Format Errors:** "Format Error" is a significant error type, especially for PoG (GPT-4) on the CWQ dataset.
* **Model Performance:** GPT-4 generally exhibits lower "Others Hallucination Error" compared to GPT-3.5, suggesting improved accuracy.
* **Prompting Strategy:** The impact of the PoG-E prompting strategy varies across datasets and error types.
### Interpretation
The stacked bar chart provides a detailed comparison of error profiles for different language models and prompting strategies on various question-answering datasets. The data suggests that GPT-4 generally outperforms GPT-3.5 in terms of hallucination errors. The choice of prompting strategy (PoG vs. PoG-E) can significantly influence the error distribution, highlighting the importance of prompt engineering. The prevalence of "Others Hallucination Error" across all configurations indicates a persistent challenge in ensuring the factual accuracy of language model outputs. The "Format Error" suggests that the models sometimes struggle to produce outputs in the expected format, which could be addressed through improved training or output constraints.