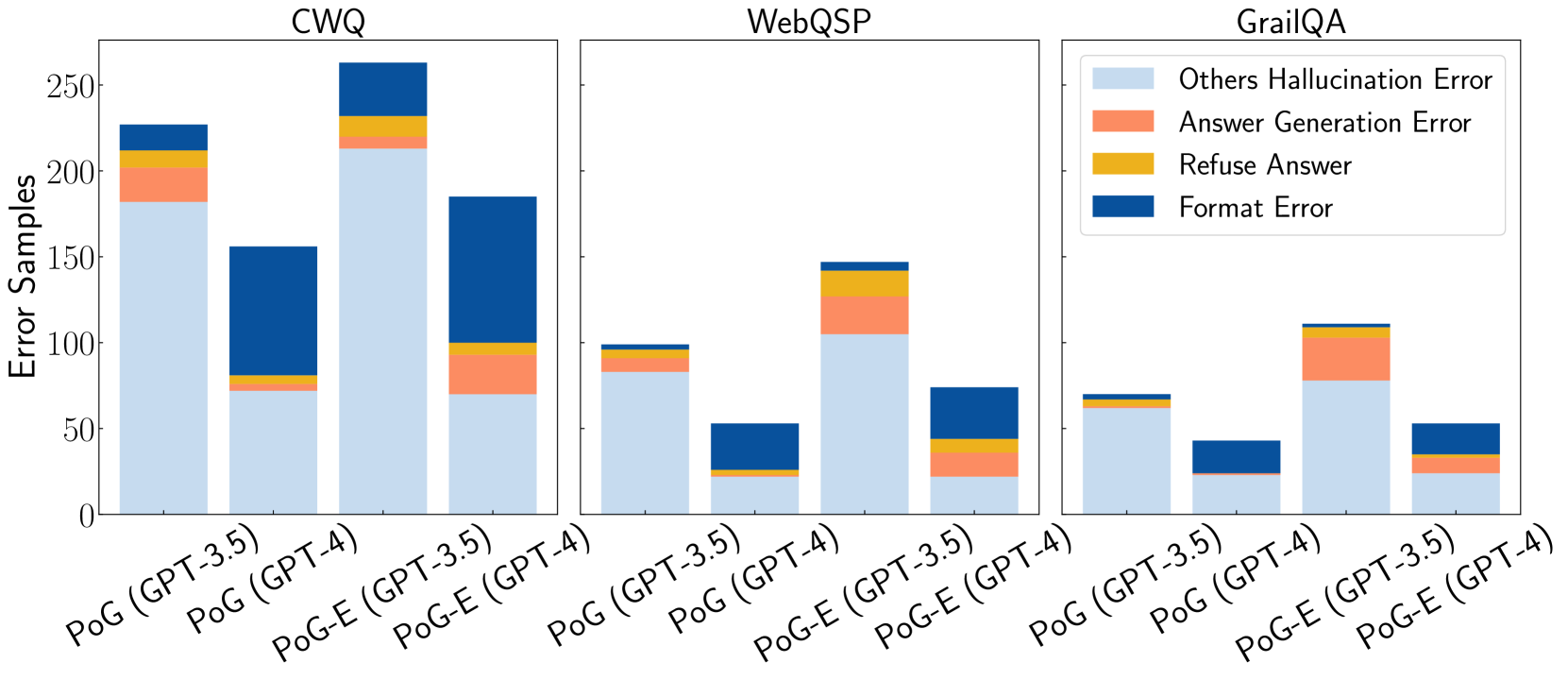
## Bar Chart: Error Samples by Model and Dataset
### Overview
The chart compares error samples across three question-answering datasets (CWQ, WebQSP, GrailQA) for two models (PoG and PoG-E) using GPT-3.5 and GPT-4. Each bar is segmented into four error types: Others Hallucination Error (light blue), Answer Generation Error (orange), Refuse Answer (yellow), and Format Error (dark blue). The y-axis represents error sample counts, with values ranging from 0 to 250.
### Components/Axes
- **X-axis**: Model/Dataset combinations:
- CWQ: PoG (GPT-3.5), PoG (GPT-4), PoG-E (GPT-3.5), PoG-E (GPT-4)
- WebQSP: PoG (GPT-3.5), PoG (GPT-4), PoG-E (GPT-3.5), PoG-E (GPT-4)
- GrailQA: PoG (GPT-3.5), PoG (GPT-4), PoG-E (GPT-3.5), PoG-E (GPT-4)
- **Y-axis**: "Error Samples" (0–250)
- **Legend**: Located on the right, with color-coded error types:
- Light blue: Others Hallucination Error
- Orange: Answer Generation Error
- Yellow: Refuse Answer
- Dark blue: Format Error
### Detailed Analysis
1. **CWQ Dataset**:
- **PoG (GPT-4)**: Tallest bar (~220 total errors). Format Error (dark blue) dominates (~120), followed by Others Hallucination Error (~80), Answer Generation Error (~15), and Refuse Answer (~5).
- **PoG-E (GPT-4)**: Second-tallest (~190 total). Format Error (~90), Others Hallucination Error (~70), Answer Generation Error (~20), Refuse Answer (~10).
2. **WebQSP Dataset**:
- **PoG-E (GPT-4)**: Tallest bar (~140 total). Answer Generation Error (orange, ~50) is largest, followed by Others Hallucination Error (~60), Format Error (~25), and Refuse Answer (~5).
- **PoG (GPT-4)**: ~100 total. Answer Generation Error (~30), Others Hallucination Error (~40), Format Error (~20), Refuse Answer (~10).
3. **GrailQA Dataset**:
- **PoG-E (GPT-4)**: Tallest bar (~110 total). Others Hallucination Error (light blue, ~60) dominates, followed by Answer Generation Error (~30), Refuse Answer (~10), and Format Error (~10).
- **PoG (GPT-4)**: ~80 total. Others Hallucination Error (~40), Answer Generation Error (~25), Refuse Answer (~10), Format Error (~5).
### Key Observations
- **Model Performance**: GPT-4 models consistently show higher error counts than GPT-3.5 across all datasets.
- **Error Type Dominance**:
- **CWQ**: Format Error is most prevalent.
- **WebQSP**: Answer Generation Error is most prevalent.
- **GrailQA**: Others Hallucination Error is most prevalent.
- **PoG-E vs. PoG**: PoG-E models generally have fewer errors than PoG in WebQSP and GrailQA but more in CWQ.
### Interpretation
The data suggests that model performance varies significantly by dataset. GPT-4 models exhibit higher error rates overall, with PoG-E performing better in WebQSP and GrailQA but worse in CWQ. The error type distribution highlights dataset-specific challenges:
- **CWQ**: Struggles with format adherence.
- **WebQSP**: Faces issues with answer generation accuracy.
- **GrailQA**: Prone to hallucination errors. These trends imply that model fine-tuning or dataset-specific adjustments may be necessary to address these error patterns.