## Heatmaps: Model Performance Comparison
### Overview
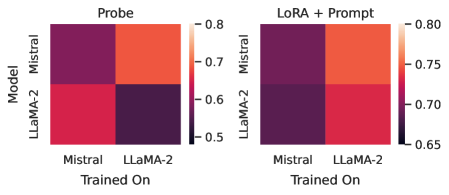
The image presents two heatmaps comparing the performance of two language models, Mistral and LLaMA-2, under different training and evaluation conditions. The left heatmap, titled "Probe," shows performance when using a probe. The right heatmap, titled "LoRA + Prompt," shows performance when using LoRA and Prompt. The heatmaps visualize the performance of each model (Mistral and LLaMA-2) when trained on either Mistral or LLaMA-2 data. The color intensity represents the performance score, with higher scores indicated by lighter colors and lower scores by darker colors.
### Components/Axes
* **Titles:** "Probe" (left heatmap), "LoRA + Prompt" (right heatmap)
* **Y-axis Label:** "Model"
* **Y-axis Categories:** Mistral, LLaMA-2
* **X-axis Label:** "Trained On"
* **X-axis Categories:** Mistral, LLaMA-2
* **Color Scale (Right Side of Each Heatmap):**
* 0.8 (Top, Lightest Color)
* 0.7
* 0.6
* 0.5 (Bottom, Darkest Color)
* Right Heatmap:
* 0.80 (Top, Lightest Color)
* 0.75
* 0.70
* 0.65 (Bottom, Darkest Color)
### Detailed Analysis
**Left Heatmap: Probe**
* **Mistral (Model) Trained On Mistral:** Dark purple, indicating a low performance score of approximately 0.55.
* **Mistral (Model) Trained On LLaMA-2:** Light orange, indicating a high performance score of approximately 0.78.
* **LLaMA-2 (Model) Trained On Mistral:** Red, indicating a medium-high performance score of approximately 0.68.
* **LLaMA-2 (Model) Trained On LLaMA-2:** Dark purple, indicating a low performance score of approximately 0.55.
**Right Heatmap: LoRA + Prompt**
* **Mistral (Model) Trained On Mistral:** Dark purple, indicating a low performance score of approximately 0.66.
* **Mistral (Model) Trained On LLaMA-2:** Red-orange, indicating a high performance score of approximately 0.77.
* **LLaMA-2 (Model) Trained On Mistral:** Dark purple, indicating a low performance score of approximately 0.66.
* **LLaMA-2 (Model) Trained On LLaMA-2:** Red, indicating a medium-high performance score of approximately 0.73.
### Key Observations
* In the "Probe" configuration, both models perform significantly better when trained on the *other* model's data. Mistral performs best when trained on LLaMA-2, and LLaMA-2 performs better when trained on Mistral.
* In the "LoRA + Prompt" configuration, Mistral still performs better when trained on LLaMA-2, but the difference is less pronounced. LLaMA-2 performs better when trained on LLaMA-2.
* The "LoRA + Prompt" configuration generally results in higher performance scores compared to the "Probe" configuration, especially for LLaMA-2.
### Interpretation
The heatmaps suggest that the models exhibit a degree of specialization or overfitting to their own training data when using a probe. When using LoRA and Prompt, the models are more robust and generalize better. The fact that Mistral performs well when trained on LLaMA-2 data, regardless of the evaluation method, suggests that LLaMA-2 data might contain information that is beneficial for Mistral. The "LoRA + Prompt" method appears to improve the performance of both models, particularly LLaMA-2, indicating that it is a more effective training strategy. The lower performance when trained on their own data suggests a lack of diversity or potential biases in the original training datasets.